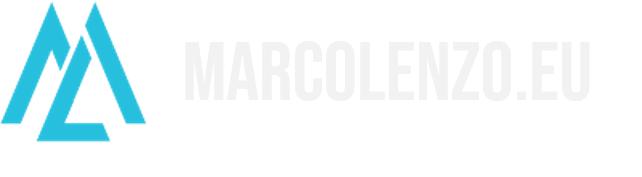
Backend for Frontend Pattern Explained

In this article, I cover the “Backend for Frontend” pattern mentioned by Sam Newman in his “Building Microservices” book. You can also find the same content in video format on my YouTube channel.
Introduction
There are times when the typical general-purpose API backed by a microservice is not enough to ensure the smooth integration of different classes of clients. The needs of a mobile application running on a flimsy network and displaying data on a small screen are very different from those of a desktop or third-party server application enjoying stable and ample bandwidth.
A way to mitigate this issue is to place an API gateway in front of our microservices. While the API gateway handles common concerns like authentication, authorization, and rate limiting, it’s also able to aggregate multiple API calls to downstream services and transform the responses; for example, it can strip out unnecessary data to limit bandwidth consumption.
In this scenario, the team responsible for the API gateway is under the huge pressure of satisfying competing requirements. As you know, it is very difficult to please everyone. Even if we try hard, we will end up bloating the gateway layer making it difficult to maintain and extend.
Sometimes frontend concerns can leak all the way to the underlying microservices. The result is the same. We end up with bloated applications, and, most importantly, we introduce the need for co-ordination between the team developing the frontend and the those developing the backend.
Backend for Frontend Explained
Sam Newman introduced the “Backend For Frontend” pattern in his Building Microservices book to tackle this problem.
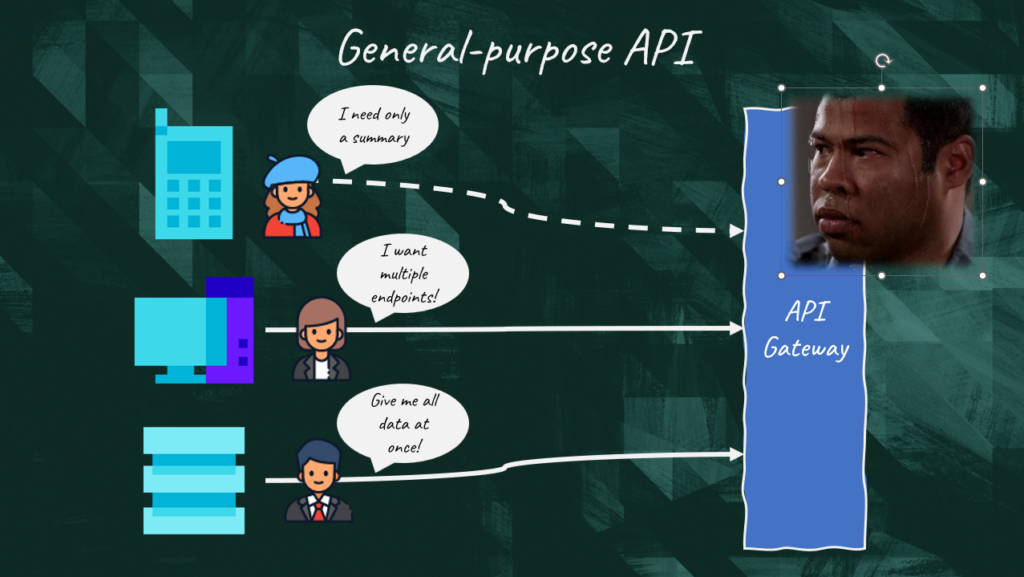
The backend for frontend is just a microservice serving a specific user interface. This way we can satisfy the requirements of each user interface without bloating our gateway or downstream microservices with presentational concerns. Most importantly we can fine tune the BFF to serve the specific requirements of its user interface.
The best way to think about the BFF pattern is to think of a User Interface application split into two portions: one running on the client device; and the other running on the server side.
For the best results, the same development team should take care of both portions. We want to avoid the need for communication between teams with different perspectives and priorities. The BFF is not a typical backend application. While your typical microservice is written in Java, Python or Go, the BFF is usually written in JavaScript or TypeScript to leverage the expertise of the frontend team.
Keep this in mind! It’s imperative that the BFF service contains only client-specific logic and behavior. We don’t want any business logic inside it. General business logic should be placed in the downstream microservices while global features can still live within the API gateway.
Another key notion to keep in mind is that it’s perfectly fine to couple the BFF with the UI it supports. It has only one goal which is to serve its frontend application thus it has to do it in the most efficient way possible. There is no need to try to generalize it since we expect no other client using it or team developing it.
How many BFF services?
The only exception to this concept is when we create a BFF to support a class of frontend applications rather than a specific user interface.
This is a major choice we need to do when we leverage this pattern:
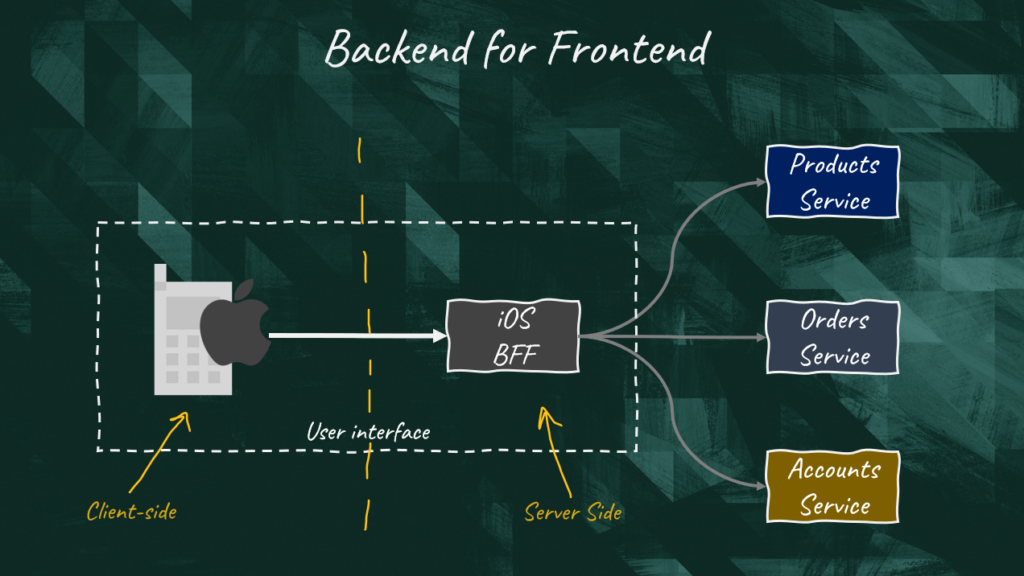
- Should we create one BFF per user interface? In this setup, Android and iOS have their own BFF
- Or should we create one BFF per class of user interfaces? In other words, one BFF could server all mobile applications.
This depends a lot on the context. If you need to leverage different technological stacks, then it might be appropriate to have independent BFF services. If all you need is a lightweight version of the full API, you might get away with just one BFF.
Disadvantages of the BFF pattern
If you watch my other videos, you know what I’m going to say. Everything has a cost! So, before we rush to use the BFF pattern in our next design, let’s understand what the drawback of this approach is.
The main concern around the BFF pattern is code duplication. There is a high chance that the different user interfaces need similar data from the BFF, especially if they belong to the same class. That means different BFF end up exposing similar interfaces. Additionally, the BFFs need to fetch data from the same downstream microservices, thus similar integration code is written multiple times.
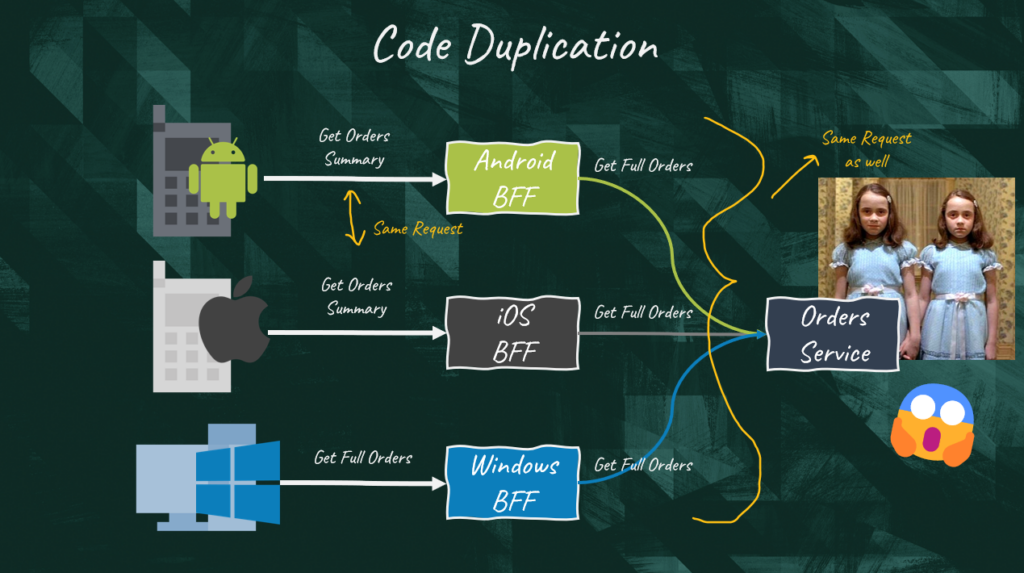
My advice is to ignore code duplication in these scenarios. Don’t try to identify which code can be reused across the different BFF services so you can place it in a shared library. If you do that, you will create dependencies between the different frontend teams, negating one of the main benefits that the BFF pattern gives them.
It’s obvious that with code duplication we are increasing the size of the codebase we need to build and maintain. This is generally a very bad idea. We should always aim at keeping the system as lean as possible. However, let’s keep in mind the original driver of the BFF pattern. The technological stacks and data needs of the different clients should be so different that it would be detrimental to satisfy their requirements in a single component.
As long as we have dedicated teams for each client / BFF pair, efficiency will not be an issue. If you don’t have enough resources and have just one team dealing with all the frontends, then the BFF pattern will add stress to a team that is already overloaded.
Alternatives
An alternative, or sometimes complementary, approach to BFF is to power up our APIs with a query language like GraphQL.
GraphQL allows the different client applications to specify exactly which data they want to retrieve, removing the need for frontend and backend teams to agree on interfaces. The backend team is meant to define the schema and implement the necessary handlers to satisfy the queries, while the frontend teams satisfy their data requirements by crafting queries on their own.
Conclusion
In conclusion, if you need to support multiple classes of user interfaces with different requirements and technological stacks, backend for frontend is going to be your BFF. [best friend forever]. However, make sure you have enough resources/developers with the right skillset before you leverage this pattern.
If the type of application you are building is mostly meant to be used by desktop clients or third-party applications, I would stick to a powerful API gateway instead, possibly supporting a query language GraphQL.
Architecture is always about trade-off. Make sure you see the whole picture before taking a final decision. Most importantly, help me out by sharing this video with your colleagues. If you want to connect with me, look at the description section… if find all the details there. Now time to learn something new!