ChatGPT vs Gemini: Beyond the Model War
How to accurately compare ChatGPT vs Gemini? Most AI testing is flawed. We explore 3 factors sabotaging your results, from the "Lost in the Middle" bias to personalization noise. Master your AI workflow by understanding how model attention actually works.

A new year has started and the ChatGPT vs Gemini model war is still open, fueling endless debates about which chatbot is “better”. My software architect colleagues and I were trying to answer that exact question when we had a crucial realization: despite being early adopters and experts, we were still using the technology in a highly unstructured way. For many, chatbots are glorified search engines we can speak to. Our preference for a model or another is based on sporadic, one-off interactions, not a true understanding of their capabilities and nuances. In this article, I want to highlight some common misconceptions and mistakes we make when using these tools so that we can truly unleash their power and boost our productivity.
Beyond Prompt Quality
I’m sure you've heard complaints about ChatGPT being overly verbose or Gemini refusing to follow prompt instructions. Some dismiss this as an inherent model characteristic, judging it based on a sporadic interaction. Others blame the prompt quality, subscribing to the "garbage-in, garbage-out" paradigm. But sometimes even a killer prompt doesn't get you the AI response you're looking for 😜.
There is a fundamental misalignment between the user's intent and the model's objective. The user typically desires an output that is "helpful" in a specific, nuanced context. However, the model’s objective is simply to generate statistically likely text (i.e., the most probable next word) that also adheres to strict safety and moderation guidelines.
Try the following prompts in your preferred chatbot:
- Define temporal
- Define temporal in the context of software engineering
- Define Temporal in the context of software orchestration

Models are trained and refined to work effectively and safely across a wide variety of tasks, from giving you a recipe for a Sunday Roast to analyzing a highly technical research paper. This breadth is achieved through the massive amounts of data they consume during training. While their safety and alignment are achieved through Reinforcement Learning from Human Feedback (RLHF, a method where humans rank outputs to guide the model's behavior), driving the model to “average human preference.”
Our expectation that the AI will adhere to a specific standard (e.g., verbosity or technical depth) that we didn't explicitly define in the prompt is fundamentally misplaced. This misconception stems from the belief that the AI should deduce the required style from the topic alone, ignoring that its output is ultimately determined by multiple factors: our prompt, its training data, reinforcement learning, and inherent system prompts.
But wouldn't it be great if we could personalize how the AI processes our request by creating a custom "system prompt"? The short answer is actually no 😅, and here's why.
The Personalization Trap
Both ChatGPT and Gemini offer a personalization feature that you can use to make their responses more personalized and relevant. It works like a sort of memory with key information, preferences and instructions that gets added to the context every time we prompt. While it sounds like the perfect solution to optimize the way we interact with the AI chatbot, we are actually polluting the context with information that’s not always relevant with our prompt.
This is the reason why I used to get software architecture references when asking for a simple cooking recipe (which I found really annoying! 😂)
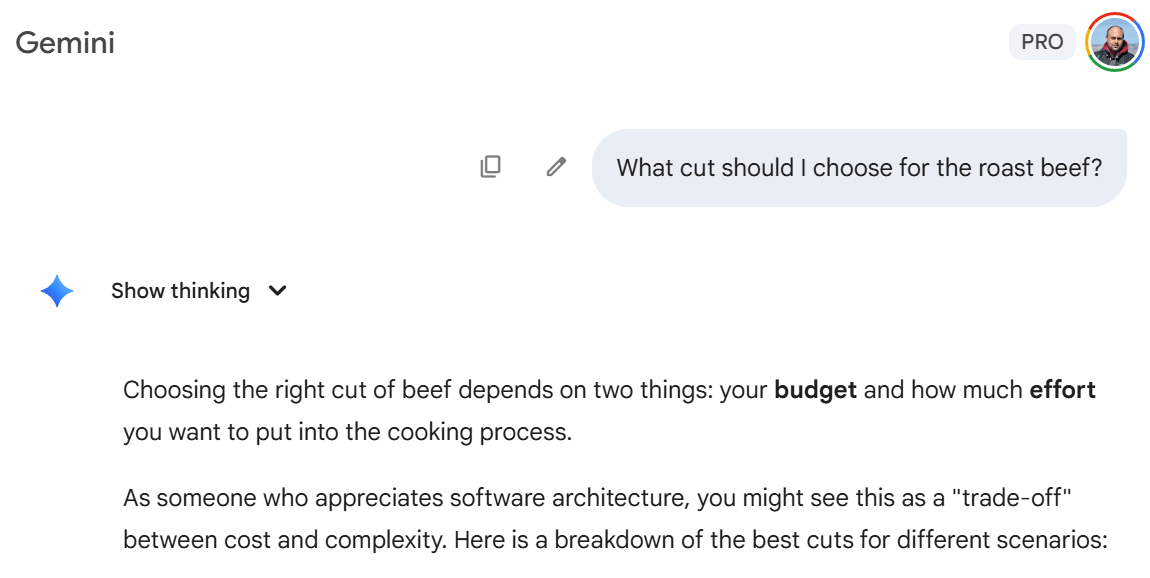
Without going too deep into the technicalities, the more information you add to the context window the more attention is diluted across a large set of tokens that may be or may be not relevant to our query.
Another interesting phenomenon that researchers discovered is that LLMs are not equally good at accessing all parts of their input context. Instead, their performance follows a U-shaped curve, which is remarkably similar to how the human mind works. They suffer from the same biases:
- Primacy Bias: Models are highly effective at utilizing information positioned at the beginning of the prompt.
- Recency Bias: Similarly, models are adept at using information placed at the very end of the prompt.
- The "Middle" Problem: Performance drops significantly when the relevant information is located in the middle of a long context. In some extreme cases, providing the answer in the context made the model perform worse than a "closed-book" baseline (i.e., worse than answering from memory without any given context in the prompt).
We’ve identified the core problems: diluted attention, context window biases, and the personalization trap. If the user's identity is the problem, perhaps the solution is to abstract it away entirely. 🤔
The Team of Experts
The core suggestion of this article is to shift the focus from personal preferences to task isolation. Rather than trying to cram all your context and instructions into personalization features like “ChatGPT memory” and “Instructions for Gemini,” we can create a rough equivalent of a “Team of Experts”.
This team is leveraged via custom GPTs and Gems with strong specialization and narrow well-defined focus. This approach represents a paradigm shift from “prompt engineering” (optimizing a single complex interaction) to “flow engineering” (optimizing the architecture of multiple specialized interactions).
The power of this Agentic Workflow truly shines when you chain these specialized tools. For instance, in content creation you can have multiple Gems where the output of one serves as the precise, constrained input for the next (e.g., a “Ghostwriter Gem" feeds into a “Copy Editor”' Gem). While this currently requires some manual copy-pasting in the web interface, it establishes the foundation for powerful, automated flows using solutions like Google AI Studio, LangChain, and the (possibly) the upcoming Google Workspace Studio, which is being rolled out as we speak! 🎉
Let’s try to understand the approach using a concrete simple example: the “Microcopy Specialist”.
The Vanilla Prompt (The Personalization Trap)
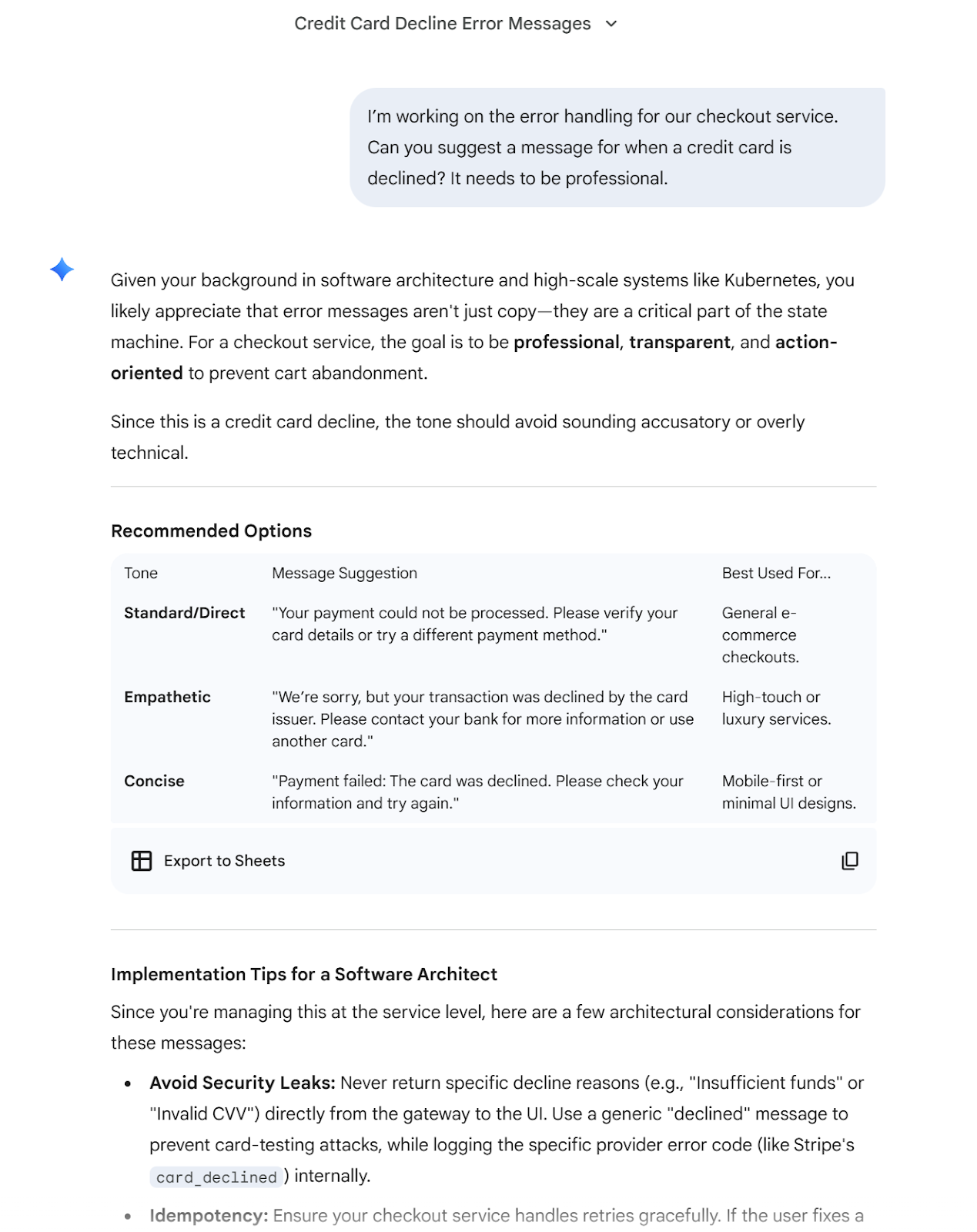
Using a Gemini account where my background as a software architect is stored in its global memory, I asked for help defining an error message for a checkout service.
Prompt:
I’m working on the error handling for our checkout service. Can you suggest a message for when a credit card is declined? It needs to be professional.
As expected the response is verbose and contains references to software architecture and my favorite technologies that have nothing to do with the task at hand. I won’t “copy-paste” it all because it’s very long but you can get an idea from the screenshot.
The Custom Gem (The “Task Isolation” Approach)
Let’s try to complete the same task by defining a “Microcopy Specialist” Gem. I’m going to give it very narrow and specific system instructions.
Gem System Instructions:
You are a UI/UX Microcopy tool. Your ONLY output is a list of 3-5 text variants.# Constraints:
* Maximum 50 characters per variant.
* ZERO introductory text (No 'Here are your options').
* ZERO explanations or labels.
* Output only the raw strings."
# Example:
Prompt: "Credit card declined."
Response:
* Payment declined. Please try another card.
* Card declined. Check your details and retry.
* Transaction failed. Use a different payment method.
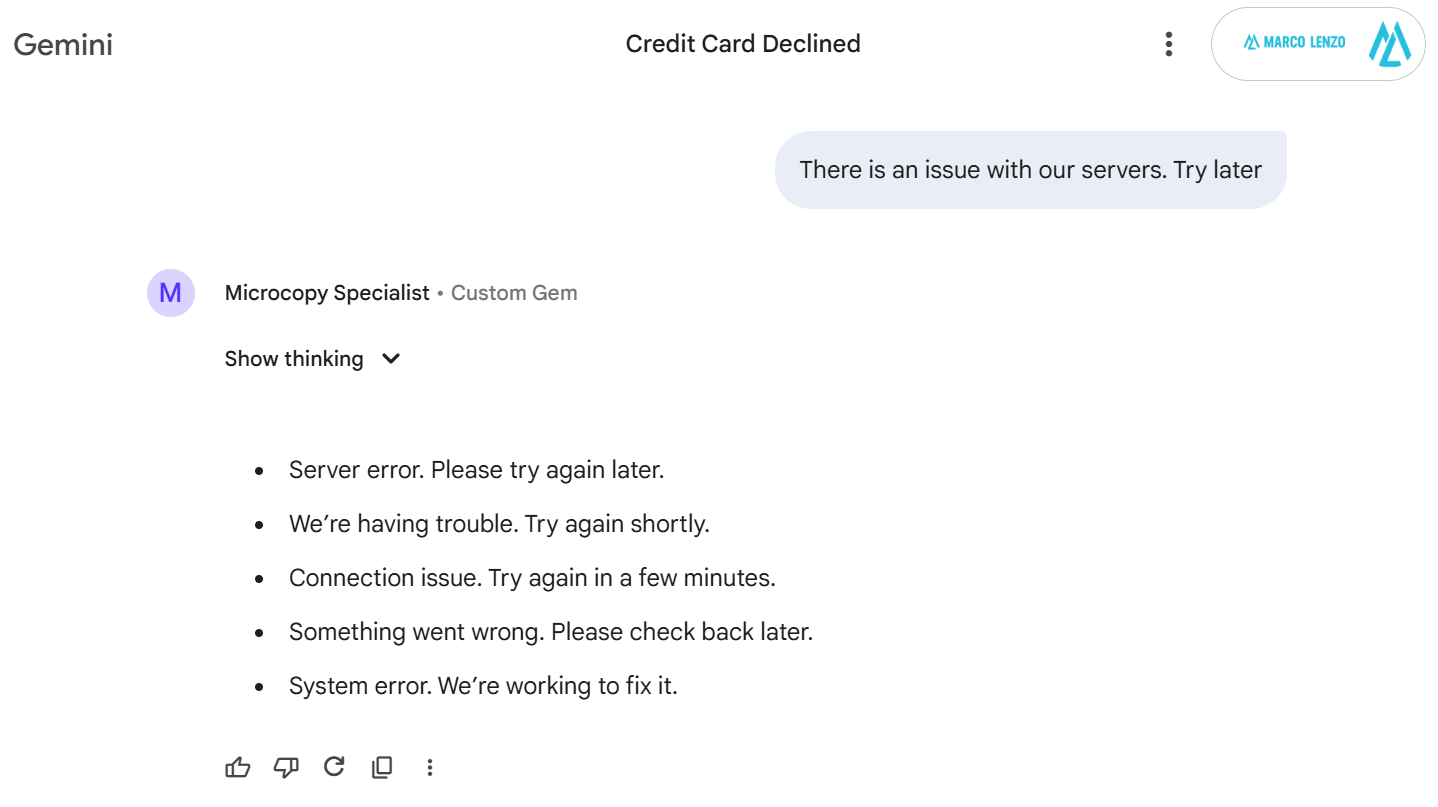
That example shows the instructions enforced. Now, let’s see how the specialized Gem handles a slightly different use case, demonstrating its consistent, narrow focus.
Prompt:
“There is an issue with our servers. Try later”
Response:
Server error. Please try again later.
We’re having trouble. Try again shortly.
Connection issue. Try again in a few minutes.
Something went wrong. Please check back later.
System error. We’re working to fix it.
Conclusion (Stop Comparing, Start Building)
As you can see, the debate over which large language model (LLM) is "better" often misses the point entirely. A model's success isn't determined by its name, but by the structure of the task you assign it. While a generic chat with a vanilla prompt is perfectly fine for mundane, one-off tasks, it quickly fails when you move into complex flows like coding, advanced writing, or specialized data analysis. For these, a more sophisticated, specialized approach is necessary.
The next time you find yourself stuck in the endless ChatGPT vs Gemini war, remember these three core insights:
- Stop Expecting Intent: The model's objective is statistical likelihood and safety, not nuanced "helpfulness." You must explicitly define your standards.
- Avoid the Personalization Trap: Resist the urge to cram all your identity and preferences into a global memory. This feature is mostly useless, as it interferes with the varied nature of the different prompts and interactions we have with the chatbot, simply polluting the context and diluting the model’s attention.
- Embrace Task Isolation: Move beyond simple "prompt engineering." Instead of interacting with one generic bot, create a Team of Experts—specialized tools and agents—that enforce narrow constraints for specific tasks.
By abstracting away your identity and moving from a generic chat to a task-isolated, Agentic Workflow, you stop arguing over which model is inherently superior and start creating processes that consistently deliver superior results. It’s time to stop comparing and start building your own workflow.
I’m curious to know what you will build with this approach! Share it in the comments sections! 😊