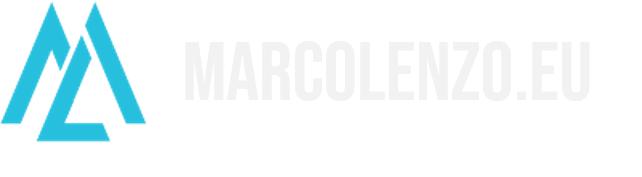
DDD Aggregates Explained

Are you building software that’s meant to last? If so, you need to understand the importance of DDD aggregates in your domain model. Aggregates are essential to build reliable, maintainable, and scalable software that stands the test of time. But why do so many developers overlook this crucial concept?
DDD Aggregates Intro
The first elements we leverage in tactical domain-driven design are entities and value objects. These are the core building blocks of DDD that allow us to define our domain and, most importantly, identify all relationships between objects, known as associations.
For example, in the context of an e-shop, an order contains one of more line items. Each line item defines exactly one product.
These objects and relationships might be subject to invariants which in simple words are rules that should never be broken.
For instance, we could have a rule enforcing that an order cannot exceed 100Kg.
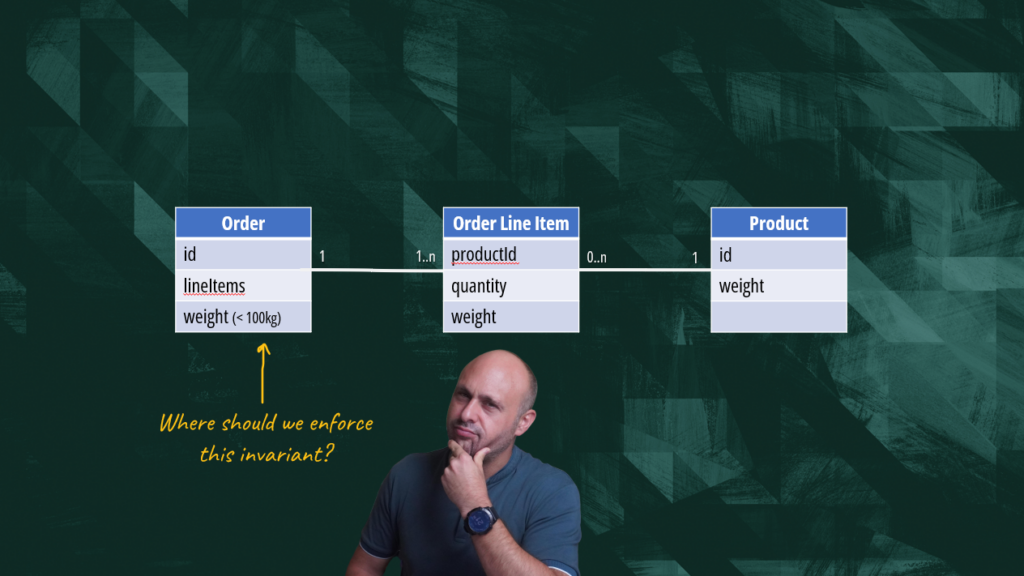
If you think about it, the most natural place to implement this validation rule is right within the “Order” class. Any time we try adding an item to the order, we first check that we’re not exceeding the maximum order weight. To verify that the invariant is applied we can create a test trying to add an item weighing more than 100Kg.
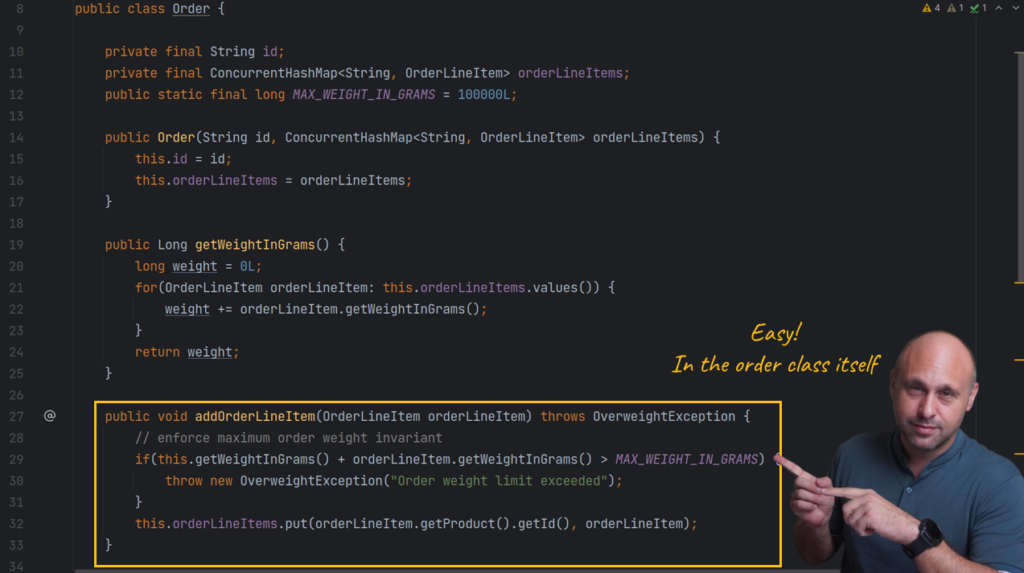
Till now everything was straightforward. Let’s complicate it a bit. Let’s imagine that business wants users to be able to modify the quantity of a particular line item. Where do we implement this requirement?
A setter within the “Order Line Item” class allows us to modify the quantity but it’s unable to verify that the maximum order weight is within the limit. This means that if we allowed direct access to this method by any object in our model, we would bypass the validation in the Order class and corrupt the state of our model. We can easily confirm this hypothesis by writing a test. As we can see, the test fails.
It becomes evident that to maintain the integrity of our model, only the order itself should be allowed to modify its line items. To further enhance encapsulation, no other object should directly hold references to line items. The order maintains ownership and regulates access to its associated line items.
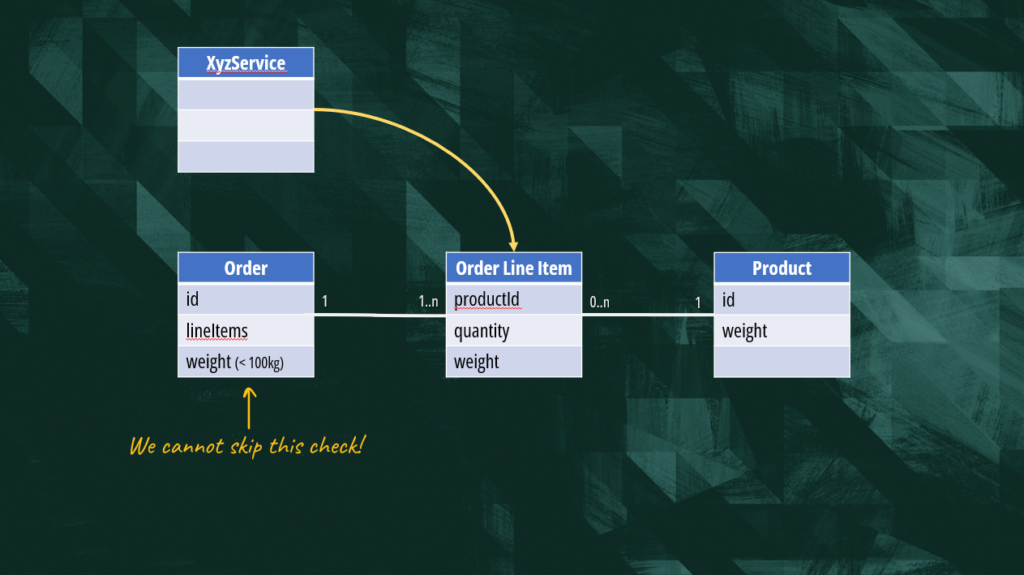
In our example, we can enforce encapsulation using the proper modifier in the “Order Line Item”
DDD Aggregates Definition
We just derived the concept of aggregate. In fact, as per Evan’s definition an aggregate is a cluster of associated objects that we treat as a unit for the purpose of data changes.
Aggregates encapsulate data and enforce business rules to ensure its integrity. Each aggregate has a boundary that identifies its members, and the root of the aggregate which is the only member that outside objects are allowed to hold references to.
In our scenario, the order class serves as the root of an aggregate containing line items.
But why are aggregates so important for building software that stands the test of time? Let’s uncover the most compelling reasons behind using aggregates!
DDD Aggregates Benefits
The first compelling reason for using aggregates is their ability to streamline complex relationships and reduce the number of associations. Associations can be intricate to implement and can make a model difficult to understand. By introducing aggregates, we effectively compartmentalize related objects, simplifying the overall structure.
Within an aggregate, only the root entity possesses a global identity, serving as the exclusive point of reference for external objects. The remaining objects within the aggregate can maintain just local identities. Any object can hold a reference to an aggregate root, while only the aggregate root can hold references to objects within its boundary. This approach simplifies massively the task of managing associations.
The second benefit of aggregates is that they harmonize the lifecycle of related objects, ensuring consistency and preventing orphaned states. Within an aggregate’s boundaries, objects can only exist if the aggregate root exists. If the root is deleted, the entire aggregate is automatically destroyed, eliminating the possibility of orphaned objects that can complicate data management.
Finally, aggregates play a crucial role in maintaining consistency across related objects. As Evans describes, aggregates are treated as a unit for data changes, meaning that any modifications made to the aggregate must adhere to the rules defined within its scope. This ensures that the state of objects within the aggregate remains consistent, upholding the integrity of the domain model.
To achieve this level of consistency, we can use ACID transactions. These transactions ensure that any complex sequence of changes applied to an aggregate is either applied in full or not at all, guaranteeing data integrity and preventing inconsistencies.
Before we try to understand why we often overlook aggregates, I want to add another reason for using them which stems from their ability to manage data consistency. While within the aggregate we must maintain strong consistency, we can adopt eventual consistency across aggregates allowing for increased flexibility and scalability.
This allows us to break down complex operations into smaller independent processing units. These units can be handled by different processes, promoting a microservices architecture that scales effectively and enhances maintainability (when done properly).
I think by now it should be obvious why aggregates are essential to guarantee the longevity of our software systems. In a few words, they allow us to minimize the number of associations we need to model in the system and ensure that strongly related objects are always in a consistent state.
Why do many developers overlook aggregates?
The final question we need to address is: “why do some teams overlook aggregates?”.
I think the most common reason is that we often tend to gravitate towards anemic models, where the business logic resides in a separate service layer rather than being embedded within entities and value objects. In this scenario, a lot of the duties we would typically slot in the aggregates are placed in a service class as well. This approach is extremely common but makes the model less cohesive and expressive and most importantly, it makes it more challenging to maintain consistency. We already covered this topic in detail in another video I’ll link in the description.
Another reason might be that teams create structures which are very similar to aggregates without a formal design. Take the example of NoSQL databases like MongoDB. In such databases, we store data as documents which usually embed related objects. These are very similar to aggregates but usually have no business logic leading to the same issues we have in anemic models.
To fully reap the benefits of aggregates, it’s essential to define them explicitly in the domain model and rigorously enforce their invariants. Only this approach ensures that data remains consistent and promotes a well-structured, maintainable domain model.
Conclusion
What’s your take? Do you use aggregates? Yes? No? Whatever is the answer, don’t be lazy and let me know why in the comment sections of the video! below! If you enjoyed the content, help me by liking the video and sharing it with your colleagues so that everyone can learn something new!