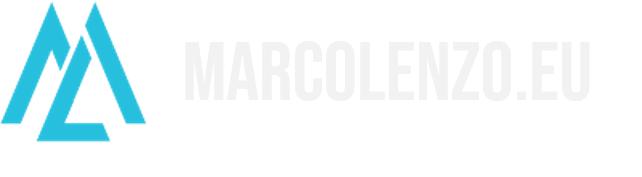
Eventual Consistency for Beginners

In this article, we will answer the following questions: What is eventual consistency? Is it better than strong consistency? And do we have any other option? Let’s discover it in the next few minutes!
Strong Consistency Defined
Strong consistency guarantees that read operations receive always the most recent data.
Let’s imagine we are storing a simple integer on a database. If one user updates its value, other users are guaranteed to see the updated value afterwards. This is the ideal scenario when building an application. It’s also expected in a monolithic setup where all data is stored in a single node.

But what would happen if we had multiple replicas of this data distributed across the globe?
Distributed System Challenges
Achieving strong consistency in a distributed system is way more complicated because updates must be replicated, which introduces several challenges.
The first is performance. Replicating data over the network takes time. To guarantee strong consistency, an update should be confirmed only after data is successfully replicated to all nodes. This makes updates slower.
The other challenge is scalability. If two users perform updates at the very same time in different nodes, strong consistency must guarantee that only one update is successful. This can cause more failures in systems that have heavy contention on “writes”.

The last challenge is availability. Replication is not possible if two nodes are unable to communicate. In this case, all updates would fail until connectivity is restored between the nodes causing a major impact on the user experience and potentially breaking SLAs.
Let’s see how eventual consistency offers a solution to these challenges.
Eventual Consistency
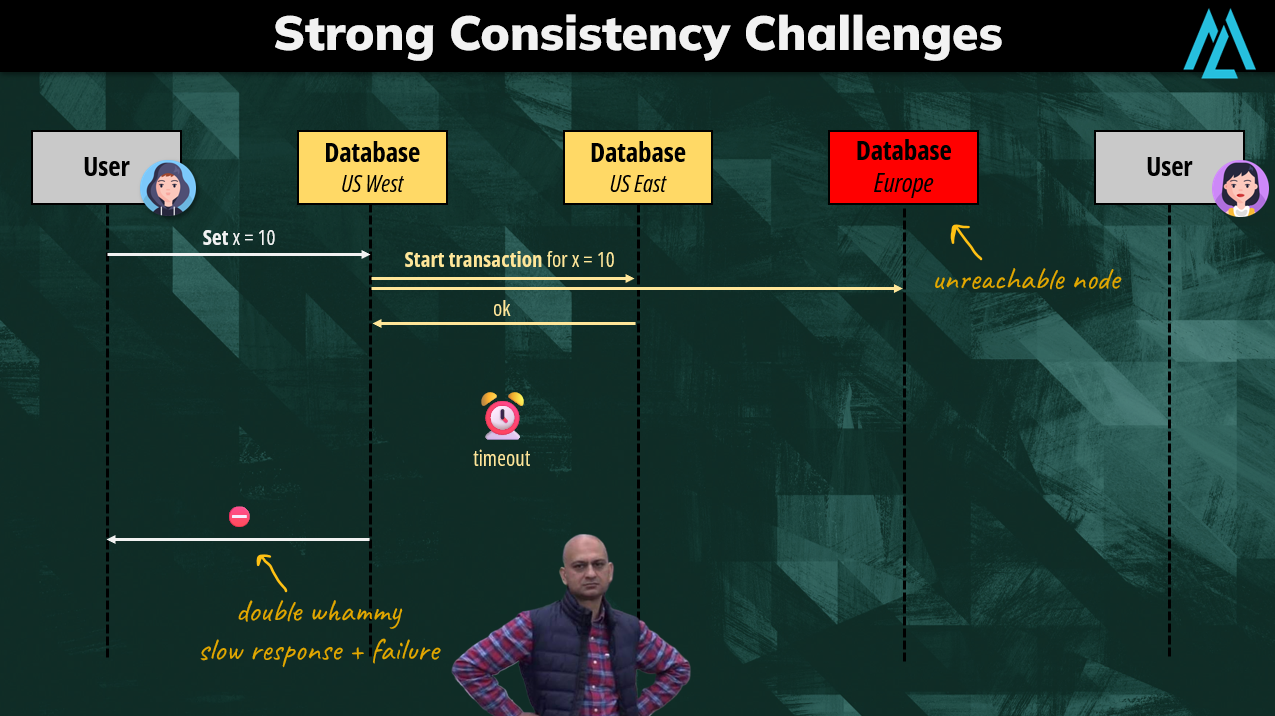
Eventual consistency informally guarantees that, if no new updates are made to a given data item, all read operation will eventually return the last updated value.
This is possible because replication is optimistic. When a user performs an update, the write is considered successful without waiting for confirmation from other nodes. The expectation is that eventually all replicas will converge to the same state.
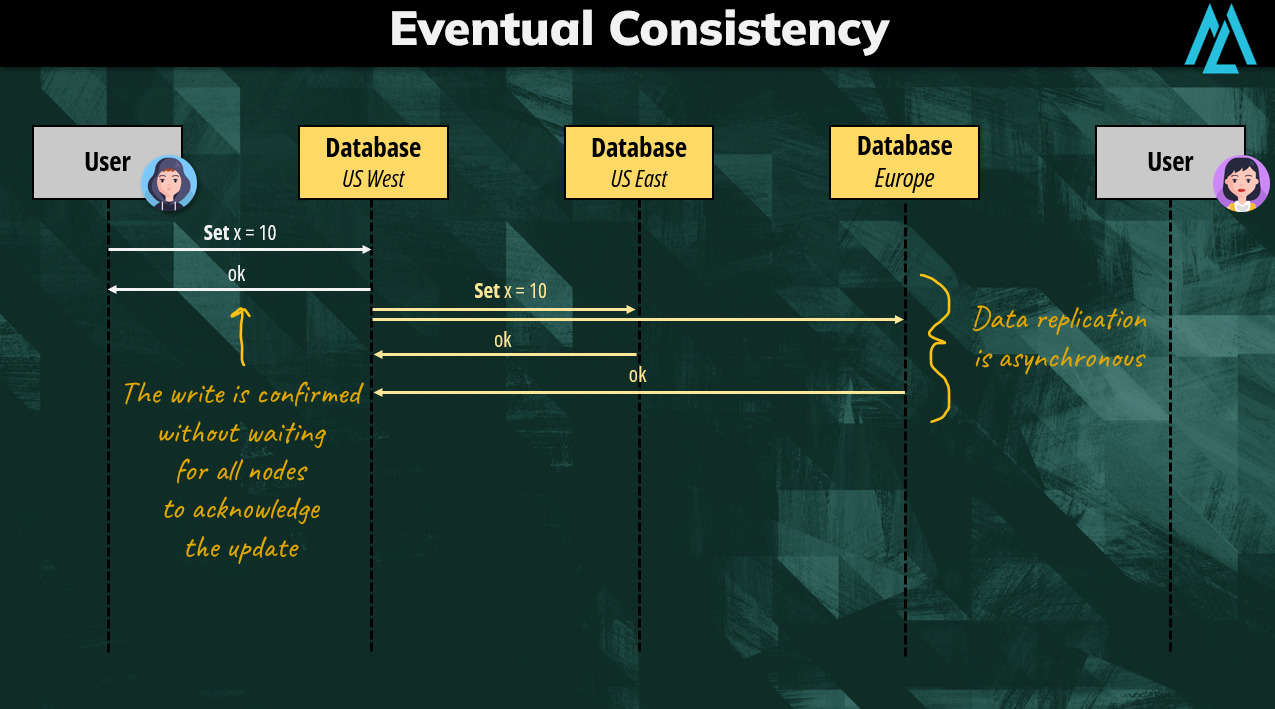
If we consider performance, eventual consistency is way faster than strong consistency because updates are confirmed without waiting for replica convergence. Obviously, this comes with a trade-off which is the possibility of stale reads. We are not guaranteed to always see the latest data.
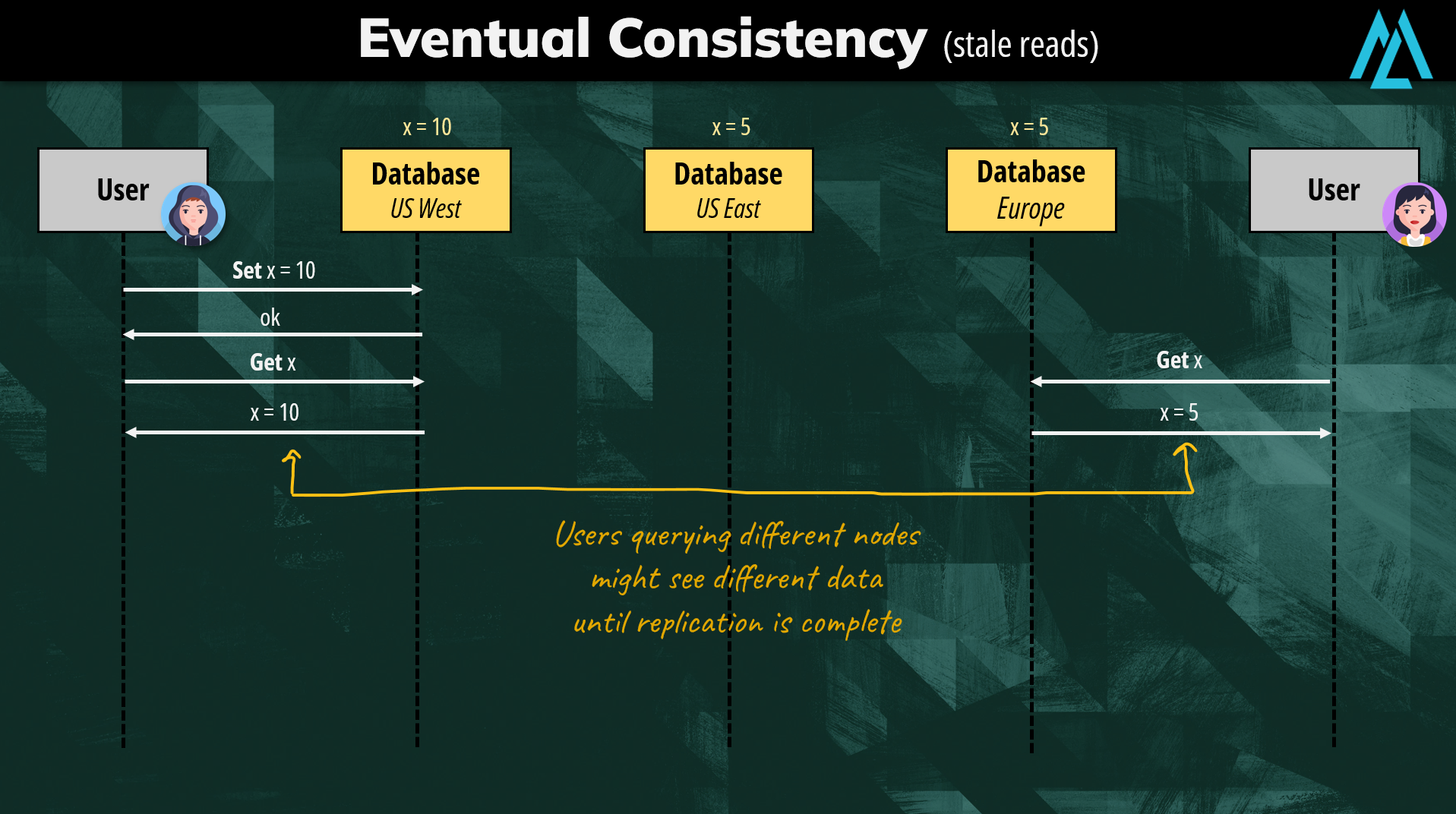
The weaker guarantees offered by eventual consistency allow us to achieve better scalability. In fact, we can accept concurrent updates while automatically resolving conflicts under the hood. A common approach is to use the “Last Write Wins” strategy where if two users updated concurrently the same data in different nodes, we would silently replicate only the most recent one.
Finally, the most important advantage is increased availability. The system can accept requests also during a node outage or network partition because it doesn’t need to wait for replication to happen.
Which one is better?
Does this mean that eventual consistency is better than strong consistency? No, it obviously depends on the type of application we are building.
Eventual consistency is preferable when high availability, scalability and performance are key objectives. A good example are social media platforms with many concurrent users. In these systems, scalability is key and forces us to deploy multiple instances of our application across the globe to deal with demand. Responsiveness is also important to keep users engaged. At the same time, freshness of the data is not extremely important. It doesn’t matter if the number of views on a video or reactions on a post are not 100% accurate.

On the other hand, there are systems where accuracy is extremely important and strong consistency is necessary. For instance, financial transactions are an obvious example where we cannot allow multiple users to withdraw funds concurrently from an account with weak guarantees. We want to be sure that funds are available when we accept a transaction.
Other models
Now, before we conclude, I want to highlight that between strong consistency and eventual consistency there is a plethora of other consistency models that lie in between. There are also database systems with flexible consistency models. For instance, let’s have a look at MongoDB.
MongoDB
Does MongoDB offer strong consistency or eventual consistency?
I know most of us think that MongoDB is eventually consistent which turns out to be the wrong answer! MongoDB offers strong consistency by default!
In fact, it supports multi-document ACID transactions which means our “writes” are atomic, consistent, isolated and durable. But how is that possible?
In MongoDB, write operations are only possible on the primary replica. This prevents other nodes from accepting conflicting updates and allows MongoDB to provide strong consistency guarantees.
By default, also reads are directed at the primary node where clients are guaranteed to read always the most updated data.
So, what are the additional replicas for?
First, it’s possible to read from secondary nodes as well. MongoDB does not prevent us from accepting a weaker consistency level for our reads. It means with MongoDB we could easily scale reads while having strongly consistent writes.
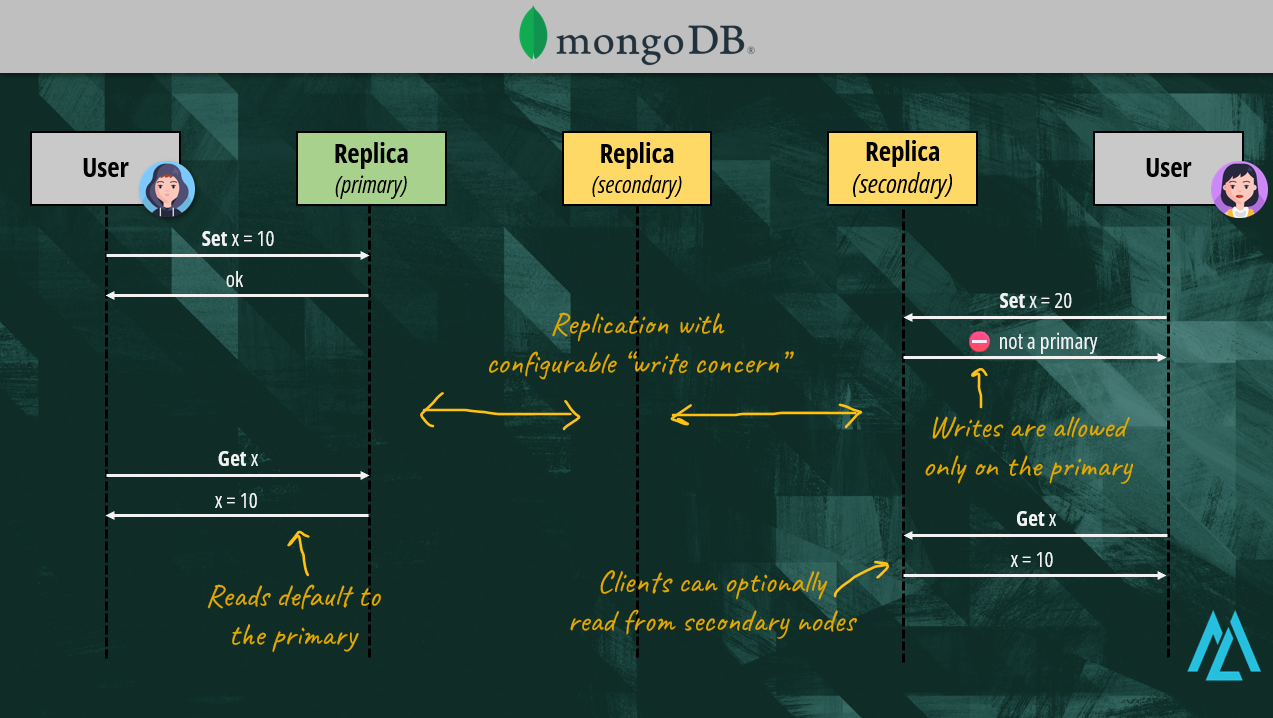
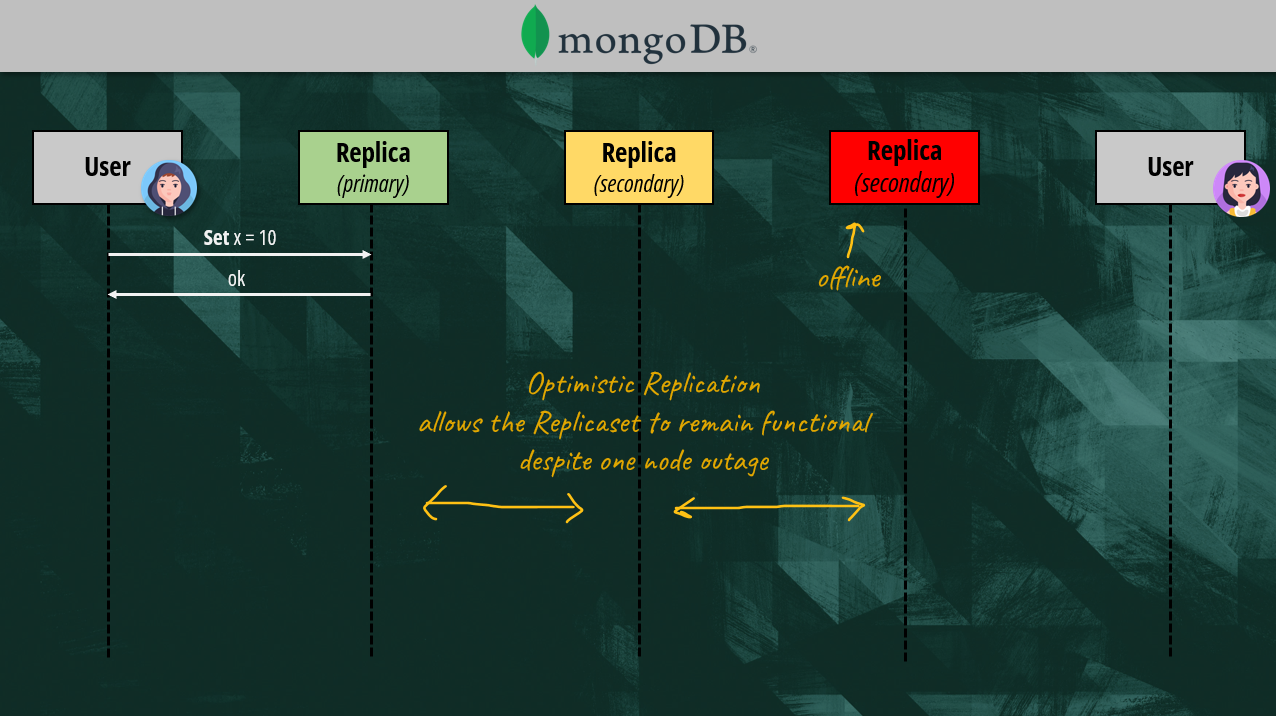
The additional replicas also provide fault tolerance and disaster recovery since MongoDB can automatically elect a new primary in case of issues.
Conclusion
Now that you have a better understanding of eventual consistency you could watch again some of my videos on microservices, APIs and events. In fact, the way data is kept consistent across microservices can follow similar consistency models and that will affect which integration pattern you are going to use.
As always, please help me out by liking, commenting and sharing my content, so that everyone can learn something new!