Kubernetes Architecture Explained

How does Kubernetes work? And what makes it so successful?
Despite its popularity, few software engineers have a good understanding of the inner mechanisms of Kubernetes such as declarative APIs and control loops. In this post, I’ll break down the Kubernetes architecture and highlight key aspects that have made it the leading solution in the cloud native world.
If you prefer you can also watch and listen to the video.
Kubernetes Explained: How it works and why it's so popular
What’s Kubernetes?
Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications.
The reasons why it’s so successful are three:
- The wide array of features it offers
- Its control loops
- Its extensible design
In essence, Kubernetes makes deploying applications and managing their environmental dependencies like network, configuration maps, secrets and volumes easier. Engineers are responsible to define the desired state, while Kubernetes continuously monitors the system and reconciles any differences, ensuring the actual state always matches the desired state.
This mechanism is also known as the controller pattern, and it’s inspired by the same control loops used in robotics and automation. In essence, Kubernetes acts as the thermostat in a room. We define the desired temperature, while Kubernetes monitors the room temperature and decides whether it has to operate the air conditioning unit or not.
Almost everything in Kubernetes is implemented according to the controller pattern.
Kubernetes is also very extensible. We can extend its API by introducing Custom Resource Definitions (CRD) and interact with them as if they were a vanilla Kubernetes resource. We can also extend its capabilities by implementing custom controllers that follow the very same pattern we described before.
This extensibility gives Kubernetes a strategic advantage on any competing solution because it makes the integration of other technologies extremely easy. Network Policies, certificate management, API gateways, service meshes, monitoring and much more are all managed within Kubernetes nowadays thanks to CRDs and custom controllers.
Good! Now that we understand why Kubernetes is so successful, let’s see the architecture behind it.
Architecture
Kubernetes is not a single deployable but it’s a set of specialized components that are deployed across one or more nodes.
There are two types of components: control-plane and runtime.
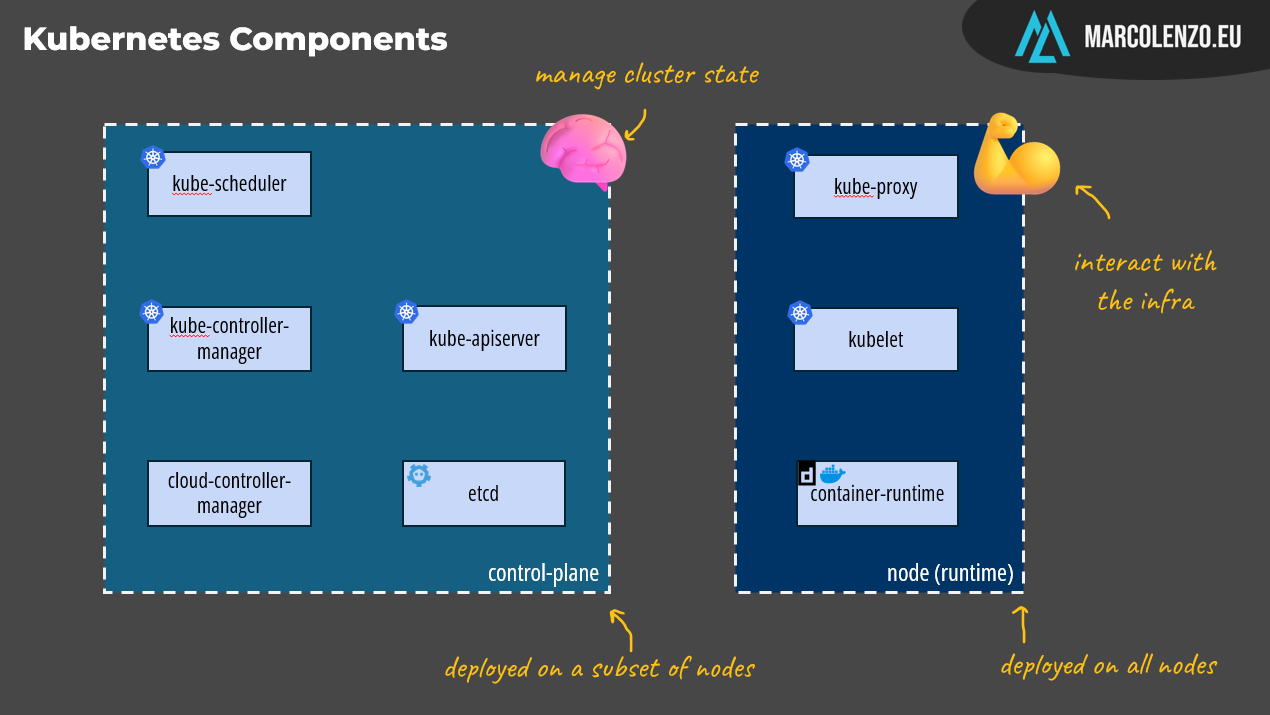
Control-plane components manage the overall state of the cluster; they act as the brain of Kubernetes, where all the decision-making happens. These components are usually deployed on a subset of nodes within the cluster.
On the other hand, runtime components—officially called node components—are responsible for interacting with the underlying infrastructure to create pods, manage containers, and configure the network rules that connect them. In essence, they are the hands of Kubernetes, executing the tasks defined by the control plane. These are deployed on all nodes.
Now. Instead of giving you a definition of each component, I’ll walk you through what happens when we execute a kubectl command. I think this is the most effective way to explain how Kubernetes works. Once you understand this, you’ll be well-equipped to work with Kubernetes and also troubleshoot some issues on it.
Let’s start.
Kubectl Flow
Imagine we want Kubernetes to deploy three instances of nginx.
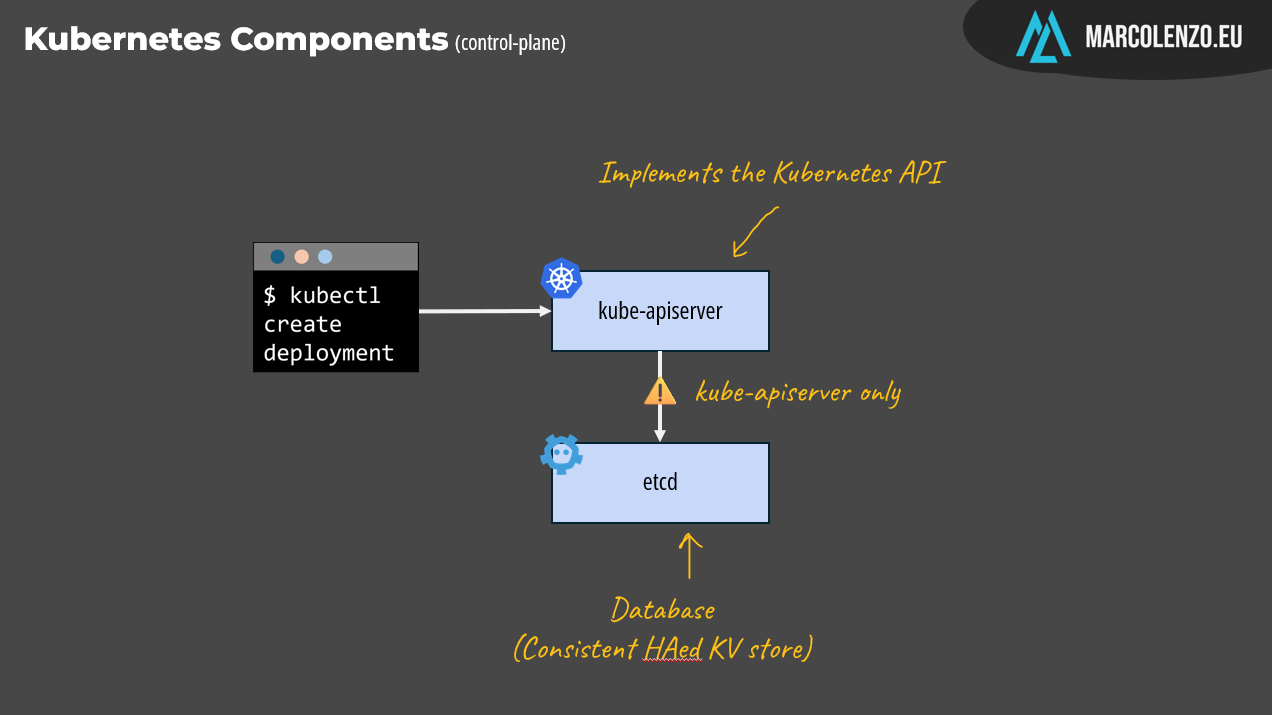
When we execute kubectl, we are actually invoking the Kubernetes API on the control plane. The component implementing the API is the kube-apiserver. This is really a special component because it’s the only one allowed to interact with the database which is etcd: a consistent and highly available key-value store.
Given its privileged role, the kube-apiserver is also the place where authentication, authorization, auditing, admission control, and validation of incoming requests take place before they are processed. Once these checks pass successfully, the desired state is saved in etcd.
Now it’s time for the controller pattern to take the spotlight. Within the control plane, three components continuously monitor the desired state by querying the kube-apiserver, compare it with the actual state, and make decisions to align the two.
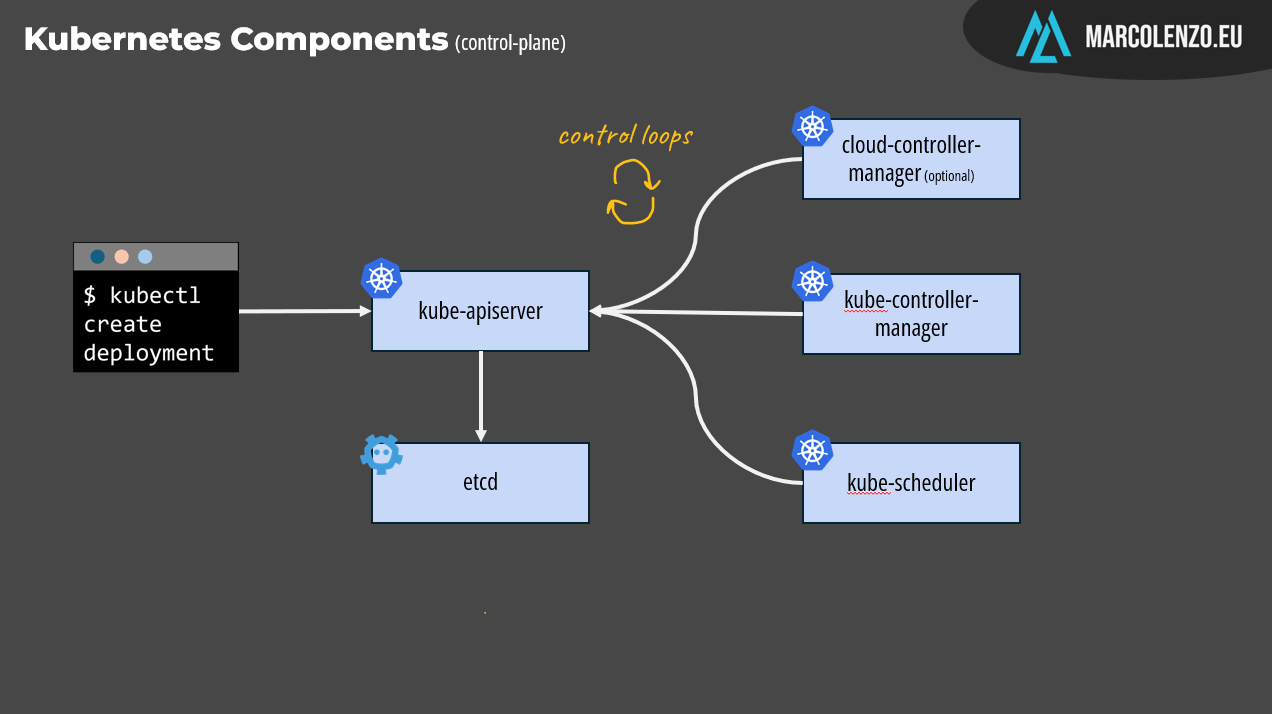
The kube-controller-manager bundles several controllers, including one responsible to keep deployments in sync with replica sets and pods. In our example, it should process our manifest and create one replica set and three pods from it.
The next step is deciding where these pods should be placed. Should they all run on a single node, or be distributed across several nodes for better resilience and load balancing? The component responsible for making this decision is the kube-scheduler, which operates as yet another control loop. It lists unscheduled Pods and assigns them to appropriate nodes based on factors like resource availability, node health, and any constraints specified in the Pod definition.
There’s also the cloud-controller-manager, an optional component designed to integrate Kubernetes with specific cloud platforms. However, it's not essential for understanding how Kubernetes operates in general.
Once all decisions are taken, runtime components step in to get the job done.
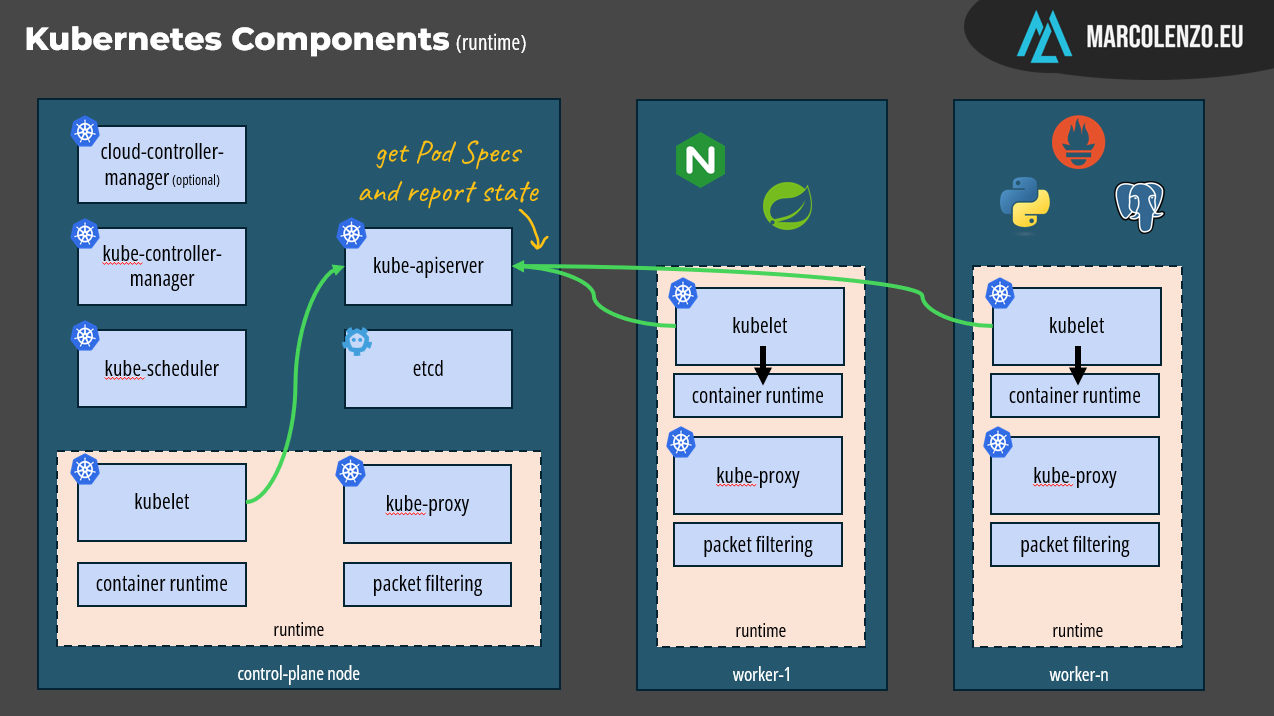
The kubelet’s role is to list pods assigned to its node and interact with the installed container runtime, such as docker or containerd, to ensure that they are created and running. It’s also responsible for monitoring their health and reporting the status back to the control plane. This is how the controllers get a view of the actual infrastructure’s state and can take corrective actions if something goes wrong, like a pod or node becoming unhealthy.
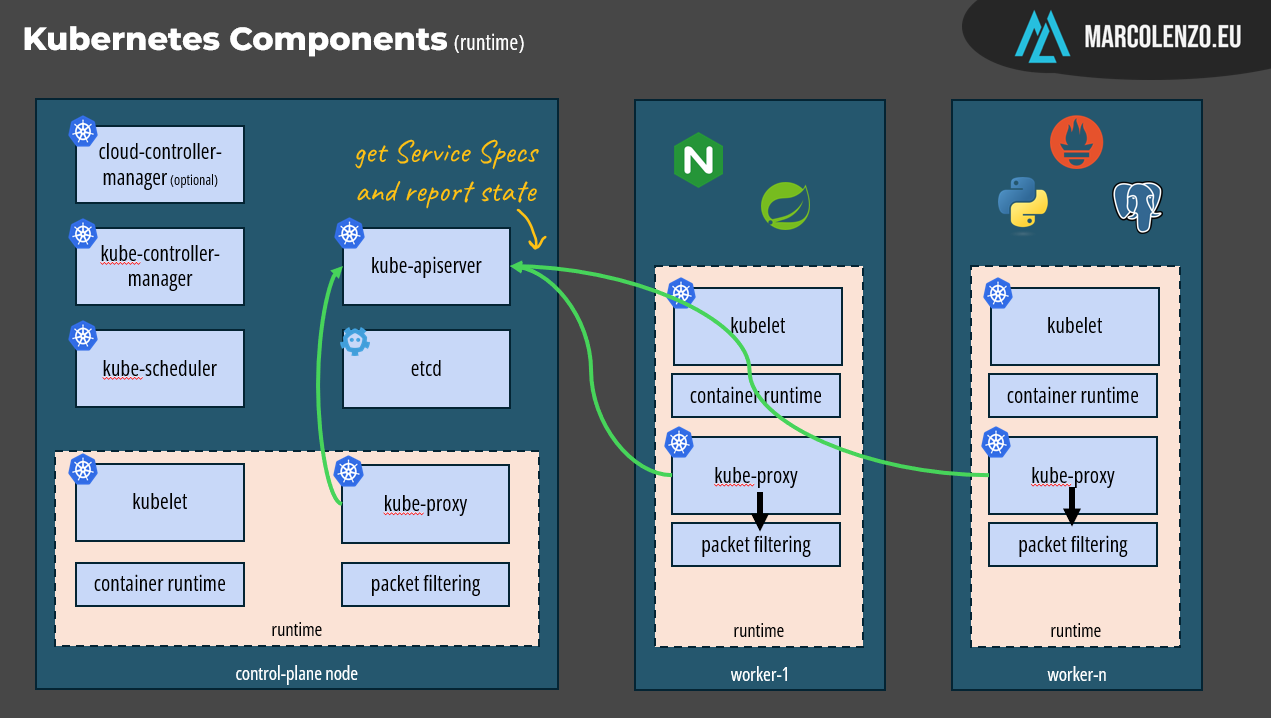
The remaining runtime component is the kube-proxy which implements the Service concept by maintaining the network rules on nodes. These network rules allow network communication to our Pods from within and outside the cluster. If there’s a packet filtering layer in our operating system, it works by configuring it, if not it routes the traffic itself. I won’t add more on this because the Kubernetes networking is extremely complex and would require its own video.
That’s all! Now you know exactly how Kubernetes works!
Support me
If you enjoyed this content, make sure to share it with other people passionate about software development and platform engineering.
If you need 1 on 1 support, go ahead and book a slot!