REST APIs Explained

What is an API?
First we need to define what an API is. An API is a contract between a provider and a user that allows them to exchange information.
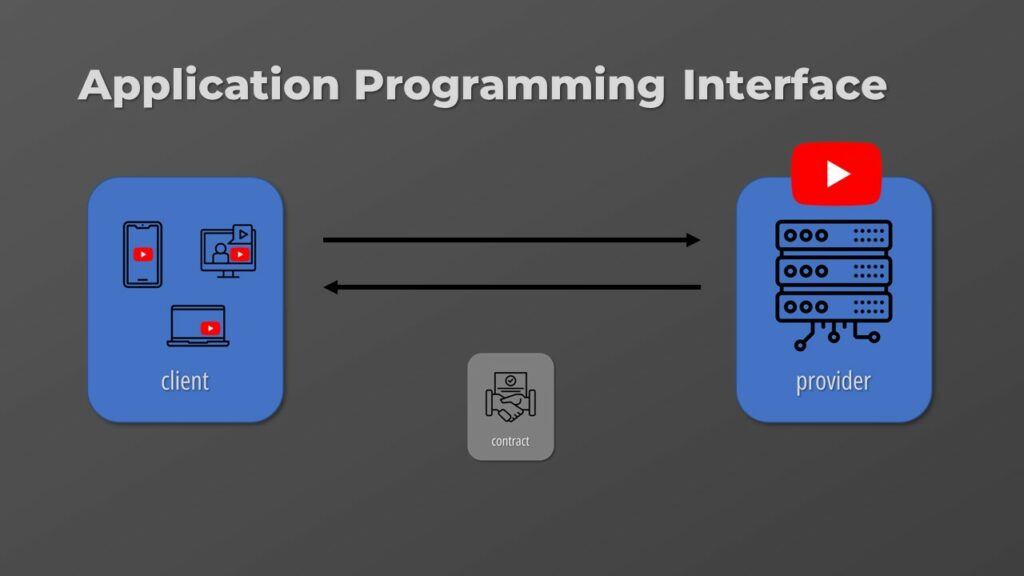
To put it into perspective, a provider is YouTube itself, while the client is the application you are using right now to watch this video. The information exchanged is the video itself, its title, description, and comments.
What makes an API RESTful?
By definition, an API is RESTful if it conforms to the constraints of the REpresentational State Transfer Architecture style created by Roy Fielding. In practice, most people understand REST API as an API served over the HTTP protocol that somewhat follows those constraints. This is not a case, because Fielding is also an author of the HTTP protocol and that explains why the HTTP semantics marry very well with REST. So although a REST API could use another protocol, let’s stick to HTTP for the rest of this article.
The 6 constraints of REST
There are six constraints defined by the REST architectural style:
- Client-Server architecture
- Stateless
- Cacheable
- Uniform Interface
- Layered System
- Code on demand
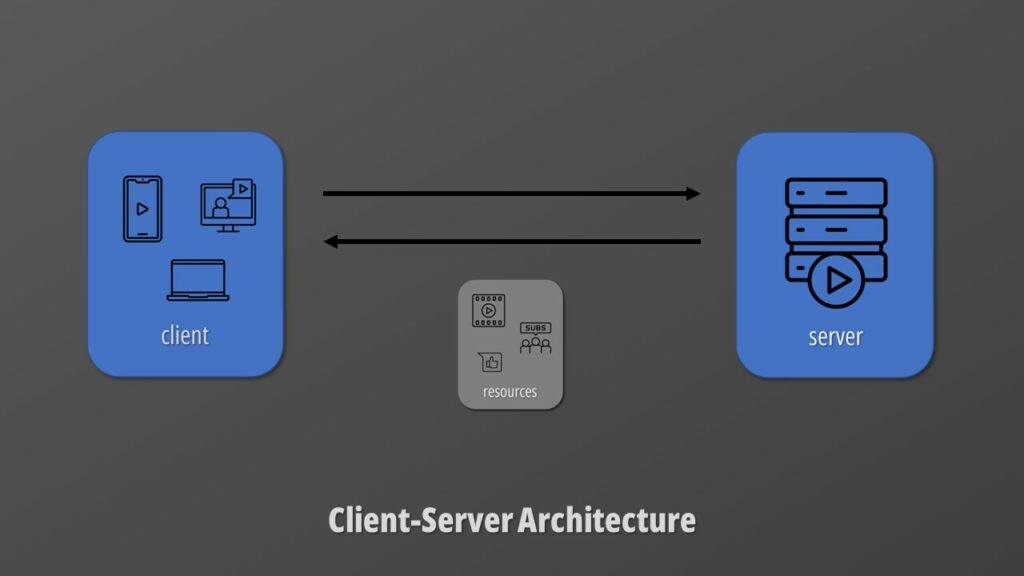
Client-Server architecture
The first one we have already seen. REST suggests that our systems should be made of clients and servers exchanging data organized as resources.
The main advantage of this approach is that we can implement and scale clients independently. Which is exactly the typical use case. The number of clients is larger than the number of servers hosting the API.
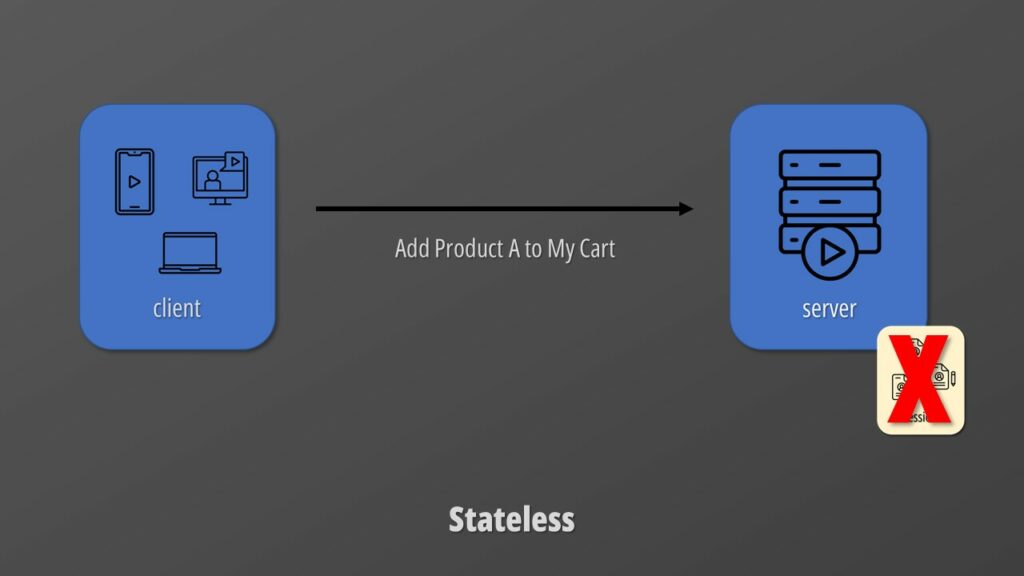
Stateless
The next constraint is stateless communication. For that to be possible, each client’s request must contain all the necessary information for the server to process it. The server should not store any context or session.
The advantage of a stateless architecture is that it is reliable and easier to scale. There is not state on the server side that needs to be replicated among multiple instances of our API which is the winning approach to deal with the “internet-scale”.
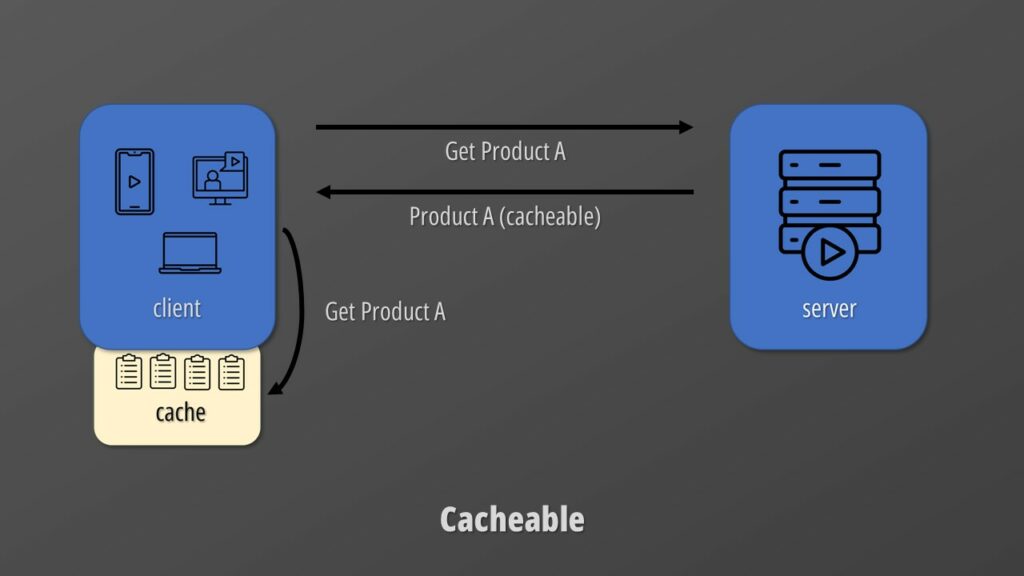
Cacheable
The server must flag responses that are cacheable. This is key to improve network efficiency by reducing communication between clients and servers. It also improves the quality of the user experience by removing the latency between the two parties.
Uniform Interface
The uniform interface is where the contract portion of the API takes shape. The goal is to have server and client communicate without sharing their implementations. The server could be a Java app while the client is a JavaScript app running on the browser. What matters is that they exchange information in a standard way.
To create a uniform interface we need to do the following:
- Identify resources
- Manipulate resources through their representation
- Use self-descriptive messages
- Use hypermedia as the engine of application state (HATEOAS)
Identify resources
Each resources needs to have a unique identifier. In HTTP we do that by giving different URLs to different resources.

Manipulate resources through their representation
When we request the product details, the server responds with a representation of the product, in this case in JSON format. We can update the resource by sending back a modified version of the representation.

Self-descriptive messages
Each message needs to be complete and contain all information for it to be processed. In HTTP we do that by using Methods (also known as Verbs), Response Codes and Headers.
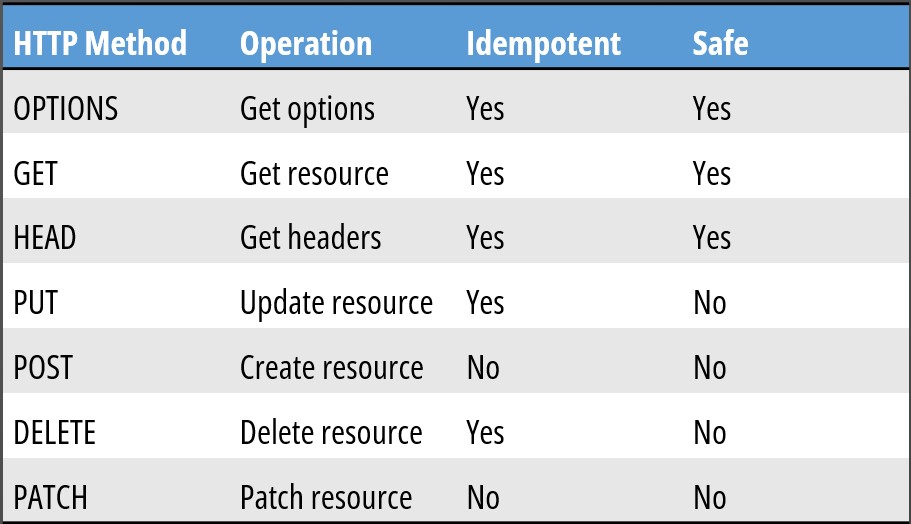
Methods are used to define what we intend to do with a request. Do we want to create a product, get its details, update it or delete it?
Methods are classified by their idempotency and safety. A method is idempotent if it produces the same outcome when the request is repeated multiple times. A method is safe if it does not modify the underlying resource.
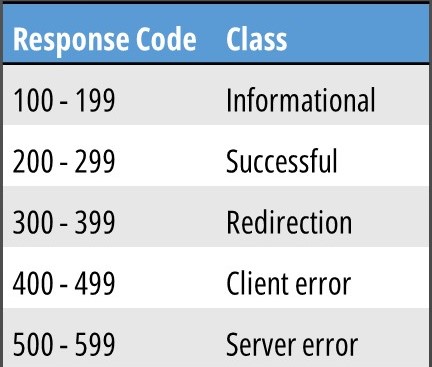
Response codes are used by the server to indicate whether the request was accepted and completed. They are divided into five classes: informational, successful, redirection, client error and server error.
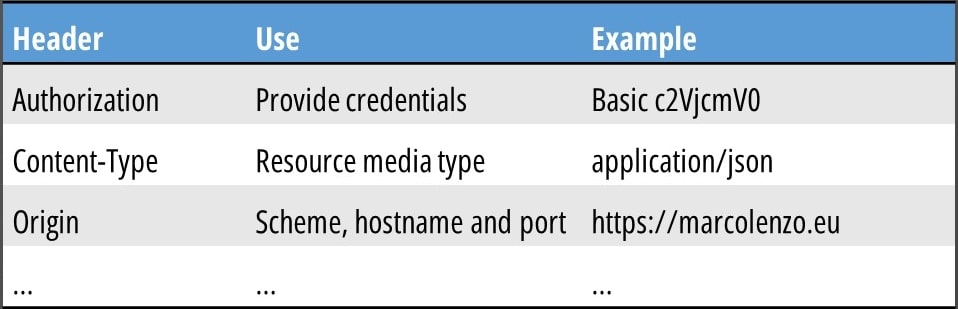
Finally, we have headers that are used for a multitude of scenarios, ranging from authentication to definition of the content-type. It is also possible to create custom headers if necessary.
Hypermedia as the engine of Application State
The last uniform interface requirement is to use Hypermedia as the engine of application state (HATEOAS). This means that our messages should include links that allow the client to browse the API. Given an initial link, the client should be able to discover all other URLs within the API. According to Fielding this is a must but in practice a lot of APIs out there do not use hypermedia.

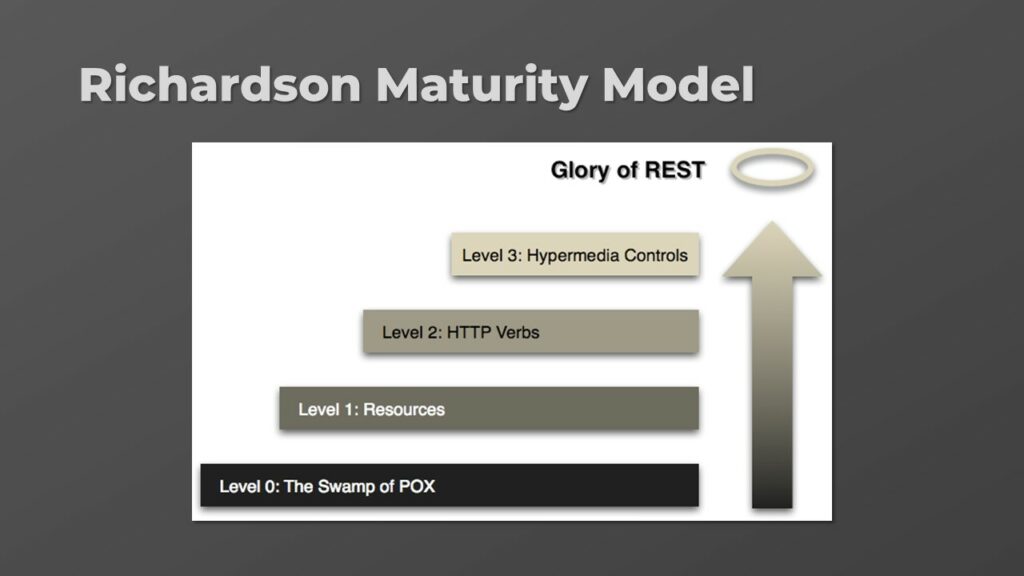
Richardson’s has created a maturity model to define how RESTful is an API. Based on its model most REST APIs in the wild reach only the second level.
In Level 0, HTTP is used just as a protocol to tunnel information between two parties. There is no use at all of the REST architectural style.
In Level 1, we start organizing our information as resources that can be reached through URLs.
In Level 2, we make proper use of verbs, response codes and headers in order to make our messages self-descriptive.
Finally, in Level 3, we reach the glory of REST by introducing hypermedia as the engine of application state and allowing our APIs to be browse in its entirety just by parsing its responses.
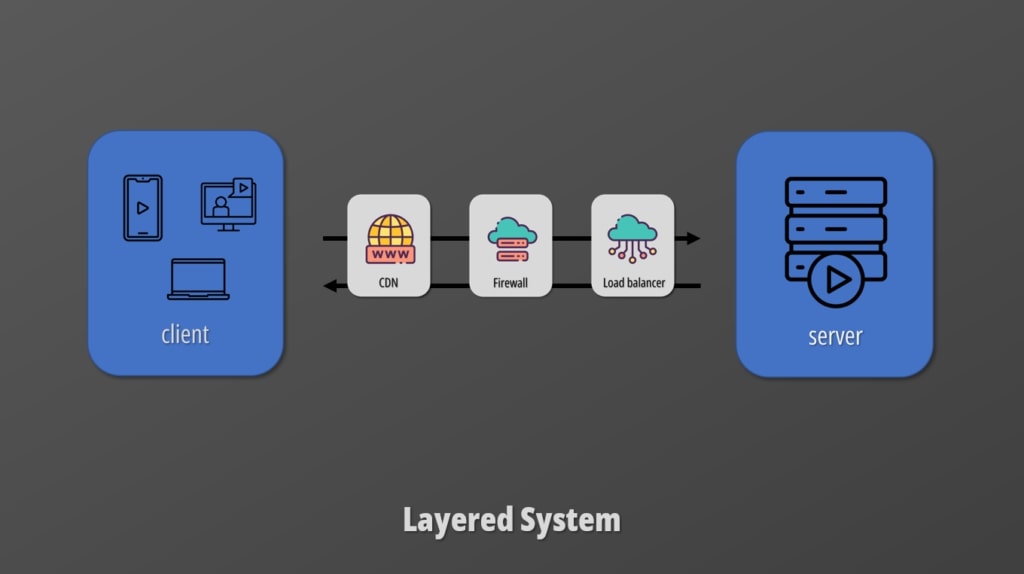
Layered System
The next constraint is a hierarchical layered system where each layer cannot see beyond the surrounding layers. We could add firewalls, load balancers, API gateways, but that should be transparent to the client which is only bound to comply with the uniform interface.
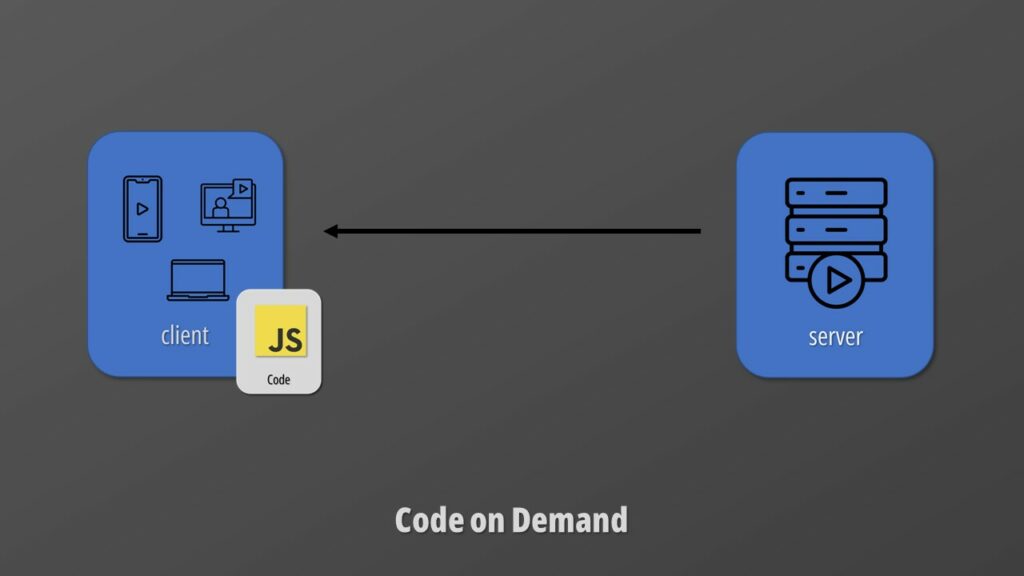
Code on demand
The final requirement is optional. Code-on-demand caters for those scenarios where code is downloaded and executed on the client side. The typical example is the JavaScript downloaded on our browsers that makes web pages dynamic.
How do we create REST APIs?
The best approach is to start by designing the API using a specification like OpenAPI. If you wish to try it out, it is extremely simple and you can do it just using the Swagger Online Editor.
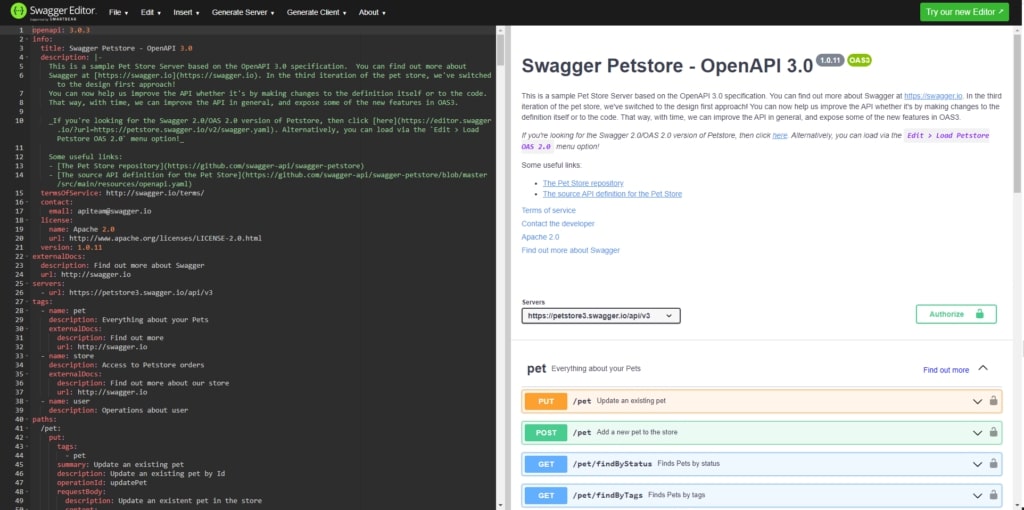
You can modify an existing specification sample on the left hand side of the screen and you will see your modification being reflected immediately on the right hand side of the screen. That is an auto generated documentation that you can share with developers, stakeholders and clients.
The same specification can be used to auto generate client and server stubs using the openapi-generator plugin.
Conclusion
It is no secret that REST APIs are dominating the Software Industry. However, their popularity is well deserved because it is thanks to the REST architectural constraint that Internet, Web Pages and Dynamic Web Applications were possible. REST is the secret sauce that allowed applications to scale to millions of clients in all the world using different devices while supported by a relatively small number of servers.