The Clean Architecture Explained

This article is a transcription of my video on the Clean Architecture by Robert C. Martin. It is part of a series of videos where we analyze some of the most popular architecture styles such as the Onion Architecture and the Hexagonal Architecture. Let’s get started!
Clean Architecture Motivation
In simple terms, the clean architecture defines a set of layers and rules we should use when coding a software application. Its goal is to create applications that can be developed and tested in isolation. Such applications are independent of frameworks, user interfaces, infrastructure, or any other external service.
What do we gain from this?
Two things. The first is that we can get right into coding the logic of our application without having to setup the infrastructure around it like databases or message queues.
The second is that we can upgrade or change pieces of the infrastructure without being forced to rewrite our application.
I know you might think that it’s farfetched to change the database or a message queue. However, I can guarantee that proper separation of concerns can save you and your company from terrible problems.
Imagine having a very large code base that stops working just because you upgraded your database to a new version. It happens. If the infrastructure concerns are closely intertwined with your business logic, you will have to refactor and retest your entire code base. These projects can take months to complete. During these months you might be producing no new features for your user base and that’s a big problem in a highly competitive market.
Let’s see how we can avoid this ugly scenario with the clean architecture!
Clean Architecture Definition
Robert C Martin aka Uncle Bob, who’s the author of many bestselling books and who also coined the famous SOLID principles of object-oriented programming, decided in 2012 to combine several architectures and solutions into one single diagram: the clean architecture.
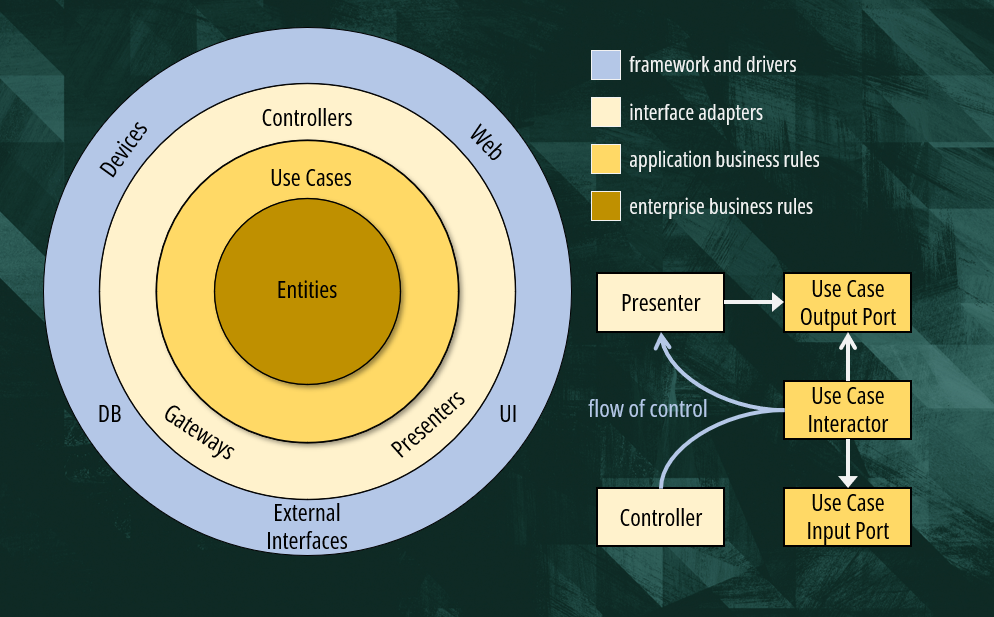
As you can see, we have four layers and only one rule denoted by the arrows: the dependency rule.
The dependency rule states that all source code dependencies can only point inward.
Now before we cover the layers in detail, I want to simplify this diagram so that we focus on its principle which is very simple.
The idea is that we place all low-level code that interacts with the infrastructure, user interface or any other service at the edge of our application. The business logic, which is the essence of our application, is placed right at the core of it. The dependency rule is there to make sure that the inner layer has no dependency on the outer layer. In simple words, no class in the inner layer can import or hold a reference to a class in the outer layer. As simple as that.
The reason is obvious. This was our initial goal. We don’t want to rewrite the business logic just because we upgrade something outside the context of our application.
If you have to take one thing home from this article, this is it. Make sure this concept is clear.
Now let’s have a quick look at the layers.
Uncle Bob splits the business logic into two kinds: enterprise business rules and application business rules. The difference is not obvious if you don’t know what an enterprise is.
In the context of a very large organization, we might have a set of rules, or policies, that must be enforced in all products or applications. These are the enterprise-wide business rules.
The application business rules are more user centric. They implement the specific use cases that we were tasked to support in our app. Such use cases can orchestrate multiple entities. Imagine a Create Order Use Case that orchestrates Products, Payments, and Logistics.
I want to highlight that Uncle Bob uses the term Entities in the diagram in a very loose manner. He is not referring to Entities as defined in domain-driven design. An entity can be an object with methods, or it can be a set of data structures and functions.
Now before I continue. If you feel confused by the difference between application and enterprise business rules. Don’t worry at all. Keep going! I’ll explain why at the end of the article!
The next layer is where we place the interface adapters which are classes that mediate the interaction between the UI or external systems with our application core.
This is a very interesting layer with no real business logic. The main objective of this layer is to translate data formats. For instance, our API can represent the Order as a simple resource. However, our business model could be using a very different and complex data structure. We don’t want the two things to be coupled. Each layer can use its own data format and we let the interface adapter perform the translation.
Finally, we have the edge layer where we interact with external systems. Nowadays a lot of the functionality in this layer is implemented for us by frameworks like Spring or ASP.NET. There’s way less code than there was 10 or 20 years ago.
That’s it!
Implementing the Clean Architecture
So how do we implement the clean architecture in a real application?
Just stick to the dependency rule. There is no need to replicate exactly the layers Martin defines. Uncle Bob says that you can have more than four circles. I say you can get away with two or three layers most times, especially if you are developing a simple microservice with a powerful framework like Spring, ASP.NET or Django.
All business logic can be slotted inside the domain layer. If you use domain-driven design, you can have all the elements of tactical DDD in here.
On the outer layer, we usually have controllers that mediate the interaction between clients and our API. If we really have complex use cases, we can introduce workflows or sagas.
If you are wondering how data is stored on the database, that’s the beauty of coding with a powerful framework. In Spring Data, we define a repository interface which is implemented automatically at runtime and wired to any service that uses it through dependency injection.
A key concept we are integrating from the clean architecture is to use different data structures for the API and the business logic to keep them decoupled. We use a mapper to perform the translation from one format to another.
Clean Architecture vs Onion Architecture
If you’ve read my previous article on the onion architecture, you must have noticed that it’s incredibly similar to the clean architecture. So, which one is better?
I prefer the onion architecture because the terminology is simpler and clearer. It’s something I can easily explain to a junior engineer without getting lost in semantics. Uncle Bob packages a lot of concepts in the clean architecture that only a skilled senior engineer can understand easily.
When producing this article, I had to delete two thirds of my script to keep it simple and relevant to most of you. I was also scared that by going into excessive detail, I would have created confusion. For instance, I skipped altogether the concept of Input and Output Ports that’s taken from the hexagonal architecture. I’ll deal with that in another article.
The core idea between the onion and clean architecture is the same and very simple: keep the core logic of your application dependency-free.
When it comes to layers, it doesn’t matter. Use just the layers you need. Not one more. Layers have a cost, and you don’t want a bunch of classes in your codebase with no purpose other than sticking to a particular architecture.
Each application solves different problems with different patterns. Every pattern has its own nomenclature, so be flexible. As long as you understand the principles behind object-oriented programming, you’ll be fine.