The Onion Architecture explained

Whether you are a junior or senior developer, it can be difficult to understand what the hexagonal, clean, or onion architectures are. But, most importantly, it’s difficult to figure out how to use them when coding a real application.
In this video, we will start by demystifying the concepts behind the onion architecture and figure out IF and HOW we can use them to build our applications. Let’s go!
Layering
In software architecture we structure our applications into layers. A layer is a logical abstraction used to group related functionality. We call them layers because we usually stack them on top of each other like a cake.
A wonderful example of this approach is the OSI model that defines the 7 layers we use to communicate over a network. In this model, each layer leverages functionality implemented in the layer underneath. The main advantages of layers are two:
- We can work in one layer without having too much knowledge about the rest. In fact, we can develop the HTTP protocol at layer 7 without understanding anything about the transmission of data at the physical layer.
- We can also swap the implementations of a layer without having to rewrite all the other layers. If we stick to layer 1, our data can travel over ethernet, coaxial, fiber optic cables, or even radio waves. But that has absolutely no impact on how we define the HTTP protocol. The two concerns are decoupled.
The Three Principal Layers (Presentation, Domain, and Data Source)
Now before we move onto the definition of the onion architecture and figuring out how to use it, let’s look at a more traditional three-layer architecture as described by Martin Fowler in his Patterns of Enterprise Application Architecture in 2002.
These layers are:
- Presentation
- Domain
- And Data Source

In the presentation layer, we place the logic to handle the interactions between users and third-party applications with our software. This could be a command line, a web page, or an HTTP REST API.
In the domain layer, we write our business logic. If you’ve seen my other videos on domain-driven design, this is exactly the layer where you place all the classes you have defined in your model, such as services, aggregates, entities, and value objects.
Finally, we got the data source layer where we deal with communication with other systems. Most applications retrieve and store data in a database, but this layer also includes other systems like messaging systems and even third-party applications.
If we start by leveraging these three layers, we’re already in a very good position. So why do we need the Onion Architecture? The answer is given by Jeffrey Palermo in 2008, the year he introduced the Onion Architecture to the world.
The Onion Architecture
The main concern of Jeffrey Palermo with the traditional three-layer architecture is that it doesn’t prevent coupling between the business logic and the infrastructure. If the infrastructure changes, there’s a high chance that we need to refactor the domain layer as well.
Imagine we wanted to change database and move from Postgres to MongoDB. Palermo believes that we should be able to do this without touching the business logic at all.
The answer to this problem is the onion architecture. As you can see, rather than stacking the layers on top of each other, Palermo defines them as circles and places the domain model at the very core of it. He does that because he wants to stress that the domain model should have no dependency or in other words it shouldn’t have any reference to another layer.
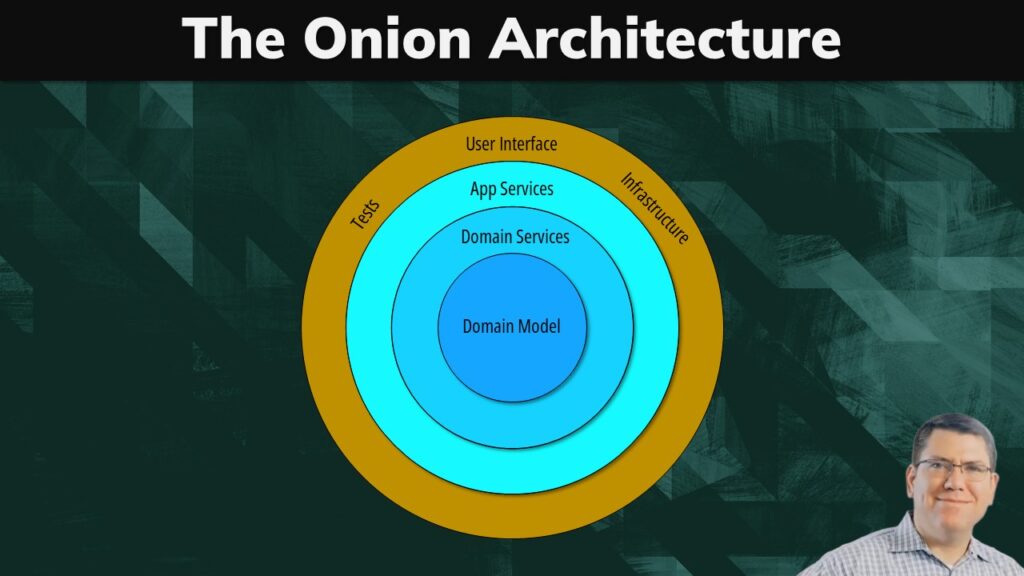
The application core also includes the domain services and application services. If you find the difference confusing, don’t stress too much about it.
Typically, domain services are stateless operations that operate directly on classes we defined in the domain model. If you are working with domain-driven design, services are effectively part of the domain model, so those two layers could be considered as one.
The application services integrate the infrastructure and user interface with the domain. They are more user centric and implement higher level concerns such a user session or a use case that can span multiple domain services. Imagine an order submission on an online shop. We might have a domain service to manage the order details, another for the product inventory, and one for the logistics. All these domain services can be frontend by a single application service that ends up orchestrating the domains and mediating between the user interface layer and the application core.
Now be careful because I’m going to mention what are the core principles of the onion architecture.
Palermo defines four principles:
- The application is built around an independent object model.
- Inner layers define interfaces. Outer layers implement interfaces.
- The direction of coupling is toward the center.
- The application core can be compiled and run separate from infrastructure.
We already understood that we want the inner core free of dependencies. The infra can depend on the application core, but the reverse is not allowed. However, how can we save our domain model on a database without having any hard dependency on it?
The solution is to define interfaces within the application core which are implemented by the infrastructure layer. For instance, we can define a repository interface to save the orders in an application or domain service. Then we implement the interface in the infrastructure layer. This way we can use the repository interface in the application core without knowing the details of how it’s implemented or where it stores the data. We could have multiple repository implementations to save to file, database, or memory.
If we do this, we still have a problem to solve. How can we link the interface with a particular implementation at runtime in a way that is transparent to the application core. We do that with Inversion of Control (IoC) and Dependency Injection (DI). In simple words, rather than having the service create an instance of the repository implementation in its constructor, we set it as an argument to the constructor. Then we should have another class, the Inversion of Control container, that’s responsible for creating the repository implementation and our service in the right order.
If you are using a mainstream programming language, you get Inversion of Control and Dependency Injection for free with frameworks like Spring Boot or ASP.NET Core. These tools scan the application at startup and wire all dependencies for managed beans or services. The beauty of it is that today we also rarely write any repository implementation because they are offered by frameworks like Spring Data and EF Core.
Now that we know the theory let’s figure out what are the advantages of the onion architecture so we can decide whether to use it when writing our applications or not.
In a nutshell, the onion architecture is not that dissimilar from a traditional one. Its main goal is to make sure that the core of our application doesn’t depend on the infrastructure. The way we do it is that any time we need a reference to the infrastructure or UI, we define an interface, implement it outside the application core layers, and wire it at runtime with dependency injection.
What do we gain by doing this?
We can test the core logic of our application without needing any infrastructure or UI. Coding our app is way easier because we don’t need a database or message queue to test its most important part. The other important aspect is that we can change the infrastructure or UI, without rewriting the application core, which was Palermo’s main goal when defining the onion architecture.
Should we use the onion architecture?
Yes and no! Let me explain.
Without any doubt, we must stick to the four principles defined in the onion architecture, especially if we work in a professional environment. If you are working on a side project, use them as well! Working alone at your own pace is the best way to learn these concepts and make them yours.
However, we don’t have to replicate exactly the layers defined in the onion architecture diagram. We need to create just the right number of layers we need in our application and not one more. If we end up with two layers that are very similar, we have a clue we’re wasting time and creating future headaches.
A simple application that leverages a modern framework like Spring Boot can usually stick to the four principles with just two layers: the core where we place the business logic and domain objects, and the web or UI where we handle the interaction with the clients or users. We usually get the infrastructure for free with the frameworks. That’s the beauty of writing code in 2024! If we really need to implement complex operations, we might add an additional layer to implement use cases, workflows, or sagas. That’s usually it.
The reason why I tell you not to create unnecessary layers is that they have a cost. Martin Fowler says that layers encapsulate some, but not all, things well. A clear example is cascading changes.
Imagine we need to introduce a new description field to our product on the UI. This is a change that will cascade to all layers in our application. What would you prefer in this case? Having 2 layers to update or 4 layers? Keep in mind each layer might include at least one object representing the product, a service class and one or more tests. I think we can agree leaner is always better!
Now that we know the onion architecture by Jeffrey Palermo, we should move onto the Clean Architecture by Robert C Martin, aka as Uncle Bob. I can tell you they are very similar, and it would be interesting to compare them to decide which one is better. Let me know if you want such video in the comments section below. Don’t forget to like and share the video so that everyone can learn something new!