The only Two Good Reasons for Microservices

Stop making microservices the goal of your architecture. There’s nothing more complex to build and operate than a distributed system. That’s why we really need to have good reasons to adopt a “microservices architecture”.
If you search the web for advantages of microservices, you’ll find this list. There’s a big problem… It’s misleading! Most of these items are advantages of well-designed microservices or software in general. If you embark on the quest to create a system made of microservices, there’s no guarantee you’ll enjoy these benefits. The only guarantee you have is that microservices are way more complex and costly to develop, especially if you’ve never used them and you don’t have a platform ready to operate them.
So the question is: when should we opt for a microservices architecture?
Team independence
A very common argument in favor of microservices is that they can mirror an organizational structure where multiple teams work concurrently and independently. This is partially true.
In fact, if we built a system where microservices are strongly coupled, we’d still need coordination between teams whenever we release.
We’ve seen a similar example in a recent video where we have a microservice whose API is invoked by many other microservices. Updating this application is difficult and expensive because it forces us to backward compatible changes.
Since there’s always a chance of error, every time we update this microservice we need to run its tests and those of all other microservices that depend on it. That makes our continuous delivery pipeline more complex.
If we decided to drop support for an API version, we’d first need to make sure that all other teams have migrated to the new version of the API. Sometimes it’s even difficult to have full visibility on which microservices depend on our application. Especially if microservices are spread across different repositories with poor documentation, lack of network policies and monitoring.
Information Hiding
The reason why many still believe that microservices favor team independence is that they help with information hiding.
Information hiding is a software design principle that advocates for hiding the implementation details behind stable interfaces. The goal is to be able to change the implementation without impacting the clients.
We can easily apply this principle in a monolith as well by decomposing it into modules. We can assign different modules to different teams and let them integrate through their interfaces.
This approach would be preferable to microservices because it avoids the cost of distributing our system over the network. As we mentioned many times, the network is a bad place which we should avoid whenever possible.
The advantage of microservices in information hiding is that they offer stronger code segregation. In the context of a monolith, a rogue developer could bypass the interface, circumventing information hiding altogether. That’s not possible in the context of microservices.
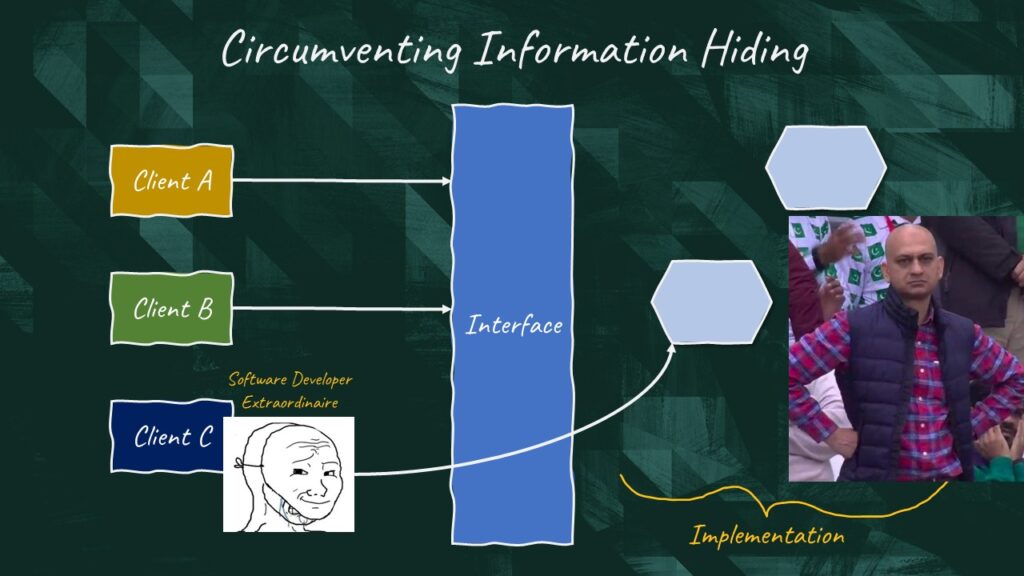
However, would you adopt microservices just because you want to prevent rogue developers from bypassing interfaces? Keep in mind that implementation details can leak through poorly designed interfaces as well. I don’t know… I’d personally consider other solutions to mitigate this issue that are way less expensive.
Independent Deployability and Data Isolation
So what are the only two good reasons to adopt microservices?
The first is the ability to release them independently. This is also a key indicator of the quality of our architecture and implementation of microservices.
If we can release a microservice without impacting the rest of the system, we can enjoy all the typical benefits associated with this architecture style.
For instance, we can scale components independently. If our system is read intensive, we can fine tune our deployments to have more microservices dedicated to serve queries. This eventually leads to better utilization of resources for the benefit of the company’s bottom line.
Independent deployability is also a guarantee that different development teams can release their code independently.
Finally, the other good reason for adopting microservices is data isolation. By splitting our monolith into independent services, we are also partitioning its data. If we have a huge amount of data to manage, microservices help us break down the complexity and size of our data model into smaller units that we can processe independently. Data processing, database upgrades and migrations are way easier when the dataset is smaller and spread across different services.
Keep in mind that everything has a cost. In this case, we are losing the ability to enforce referential integrity at the database level. So if we have duplicated data across microservices, it’s up to us to keep it consistent, possibly through events and materialized views.
Conclusion
In conclusion, never start with microservices being the goal of your architecture. You should first model your system and understand your product’s requirements. If independent deployability or data size are major concerns, then microservices might be a valid option. Otherwise, if you just want to have teams work concurrently on a system, structure your code into well isolated modules and spare yourself the pains and costs of microservices. You might want to refer to domain-driven design principles to be able to identify bounded contexts with high cohesion and low coupling. If you want to know more about this topic, visit my channel page because I have a lot of content on it. Don’t forget to share with your colleagues so that everyone can learn something new.