Building Git with DDD and Clean Architecture

In this article, I want to show you how I apply domain driven design (DDD), as well as clean, onion and hexagonal architectures concepts when I design and code a simple application. Rather than giving you a set of rules or definitions, I will explain what my thinking process is. This way you can extrapolate the core principles that drive my decisions and port them over to your specific application or scenario.
If you are unfamiliar with these topics, I suggest you reading before some of my previous articles to build a high-level understanding of them:
The application
The application I built is a partial replica of a Git client. This is a challenge part of the CodeCrafters learning platform where you are asked to build complex software like Git, Redis and Docker.
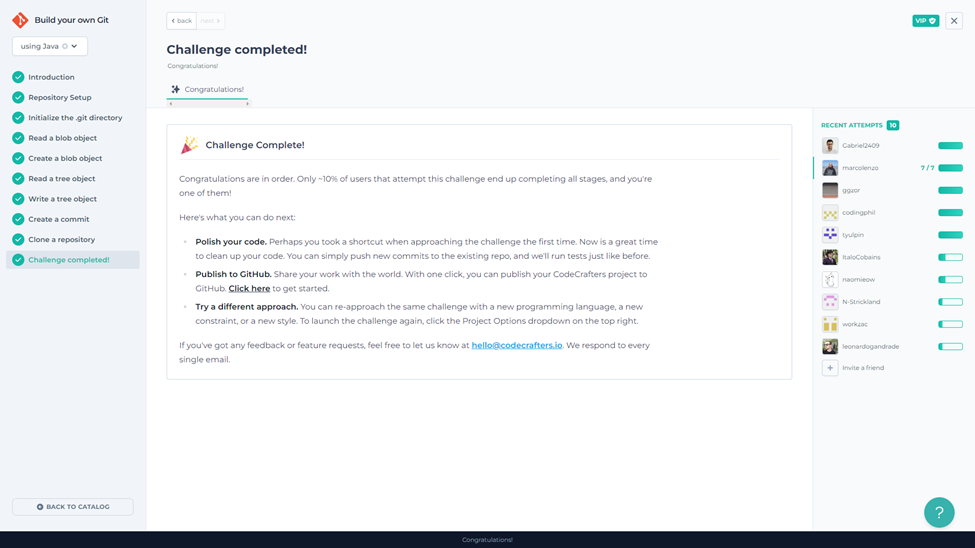
The Git challenge consists of seven stages you need to complete in order. You start by initializing a local git repository; then you move into reading and creating Git objects; and finally, you perform a full clone of a remote repository. The last stage was very tough, and it kept me engaged for a couple of days!
If you want, you can try CodeCrafters for free. They have free challenges every month. However, make sure to access with my partner link, so you can benefit from a significant discount should you decide to move to a paid subscription later on.
Understanding the domain with DDD
The very first thing I do in every project is understanding the domain by identifying the most important entities and their relationships.
Typically, I would define the scope with business or clients and the domain experts. In this challenge, I had to jump straight into coding before I was able to understand what I was meant to build. However, once I had a decent understanding of the domain, I created a model and refactored the application to match it.
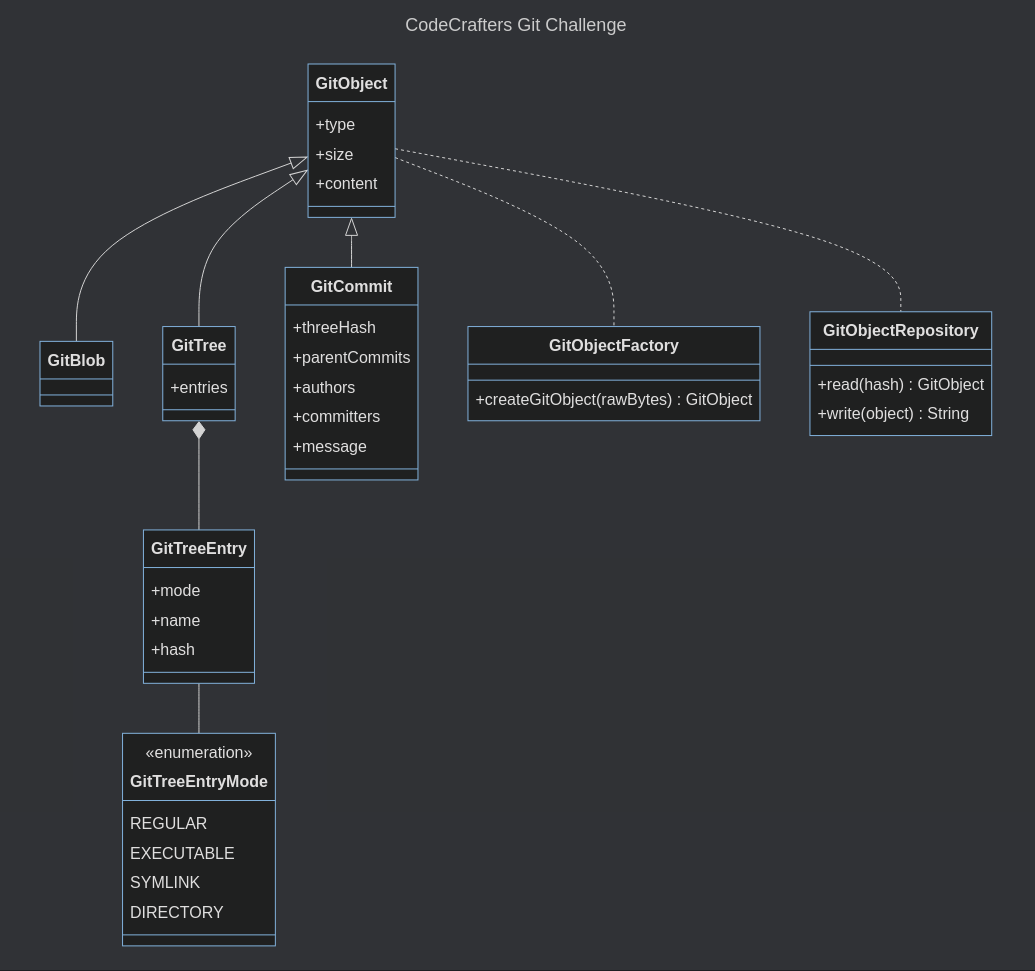
As you can see the initial version of the model was very simple.
Git stores data about a local repository in the form of compressed objects in the .git/objects folder. Each object has a type, size, and content. In this challenge, we only need to manage three types: blob, tree and commit.
My decision was to create one entity for each object type and link them together through a common ancestor: the GitObject.
I also used two other constructs of tactical DDD: repositories and factories. The GitObjectRepository was necessary to abstract the complexity of storing and retrieving objects from the data store. This allowed me to remove concerns like the compression algorithm or file management from the entities. The factory was useful to create objects from raw bytes which was something I didn’t want to code in the entities’ constructors.
package core.repository;
import core.entities.GitObject;
public interface GitObjectRepository {
public static final String DEFAULT_PATH = ".git/objects";
/**
* Retrieve object by hash
*
* @param hash
* @return The object associated with the hash
*/
GitObject findByHash(String hash);
/**
* Save object
*
* @param gitObject
* @return The hash of the saved object
*/
String save(GitObject gitObject);
}Why modeling?
But why did I go through the effort of creating a domain model? 🤔
In a professional environment the domain model is necessary to create a ubiquitous language which is basically a shared understanding of what we are building. However, I find the domain model useful also when I am working on a project alone because it helps me understand the relationships between different concepts and organize the code accordingly.
This simple structure allowed me to clearly identify the commonalities between the different object types and avoid duplicated code. It also prevented me from fitting too many concerns in a single class. Finally, it also facilitated the extension of the feature set in the last stage where I needed to map new concepts like remote repositories, references, packs, and delta instructions.
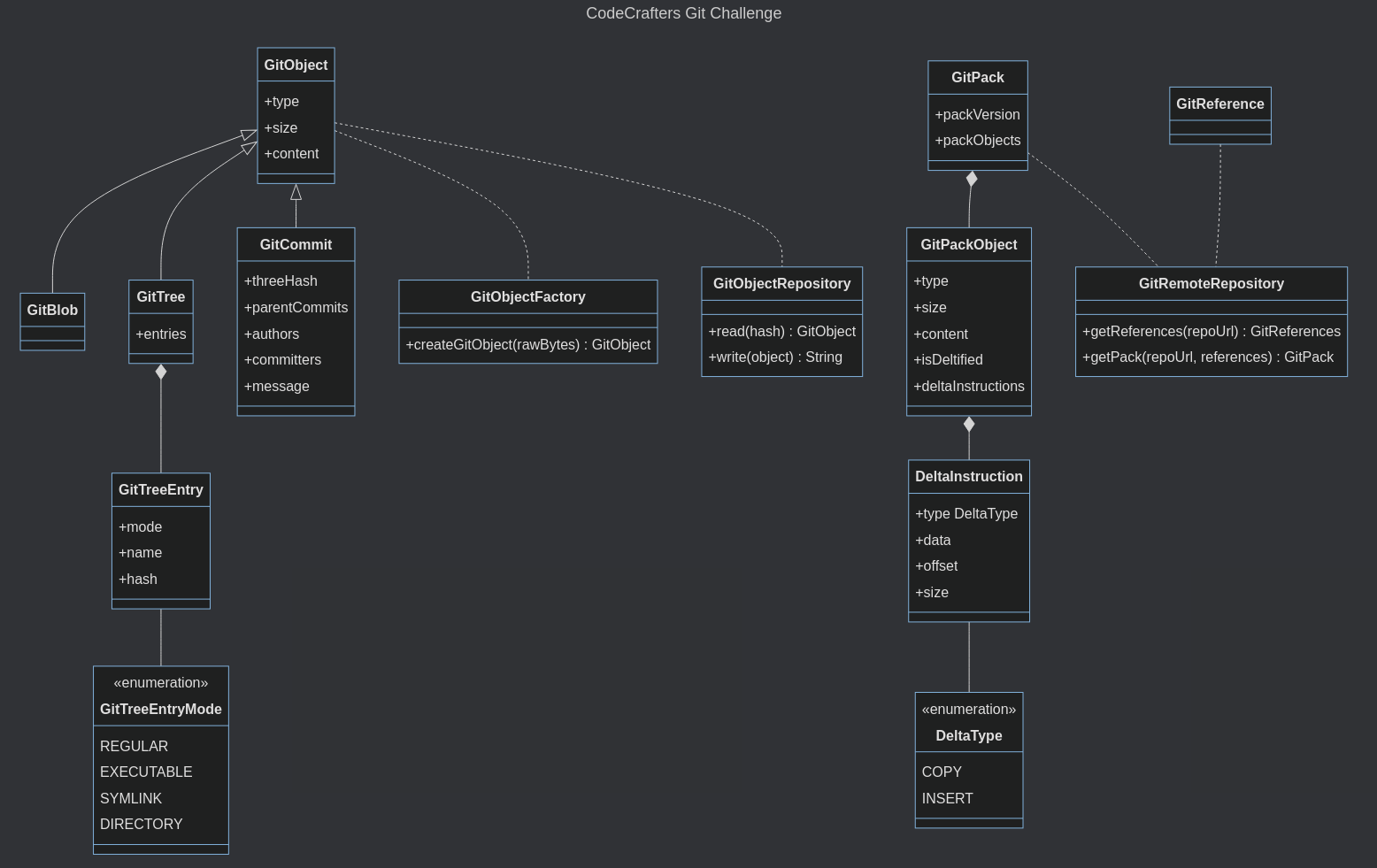
I want to highlight that I never invested time in making the model perfect or complete. I just needed a high-level map of what I’m building. The level of detail you need will depend on the complexity of your model and your stakeholders’ expectations.
💪 Pro Tip: You can use diagramming tools like Mermaid to define your diagram as code. 💪
Choosing an Architectural Style
Another decision I take at the very beginning of a project is choosing an architectural style. In other words, I define the layers in my applications and how they interact.
There are four architectural styles I always take into consideration:
- The Three-Layer architecture as defined by Martin Fowler
- The Onion Architecture by Jeffrey Palermo
- The Hexagonal Architecture by Alistair Cockburn
- The Clean Architecture by Robert C. Martin
However, rather than choosing one option and implementing it blindly, I only make sure that my application does not break their cornerstone principles. In fact, I cherry pick what I find useful from each architecture according to the scenario I need to solve.
Layers
For this challenge, I decided to stick to a three-layer architecture and detach the business logic of my application from infrastructure and user interface. This is an idea common to all four architectural styles.
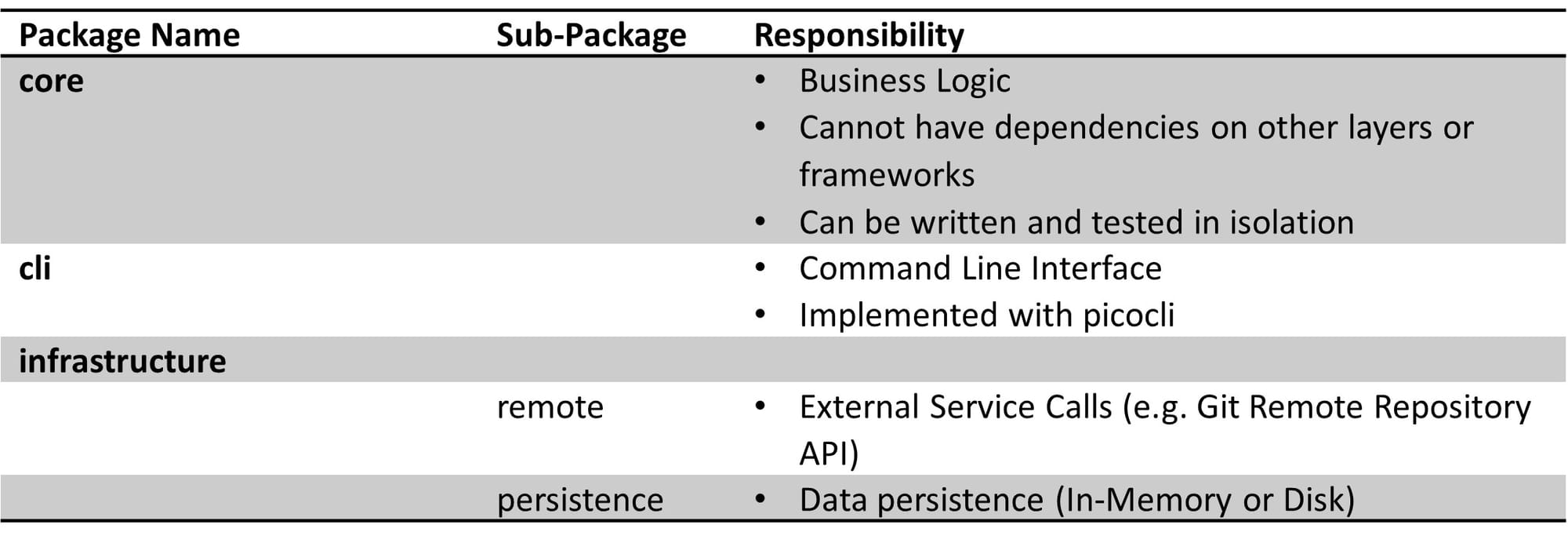
I define layers as packages or modules in Java. The core package contains the domain model and any application or domain service. This is in line with the definition of “application core” given in the onion architecture by Palermo.
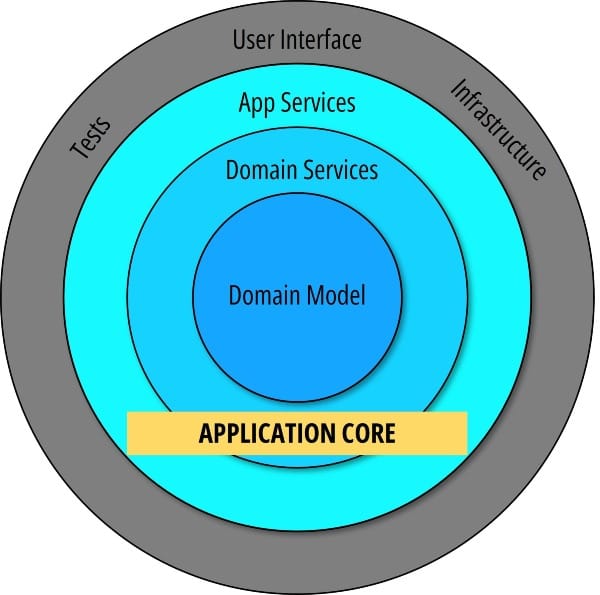
Clean, onion, and hexagonal architecture also highlight the importance of ensuring that the business logic does not depend on other layers. In practical terms, it means that any class you place in the core package cannot import classes from other packages.
But how can we store data on the database without having a direct dependency on it? 🤔
Ports and Adapters
The way I keep the core layer dependency-free is using the hexagonal architecture concept of “ports and adapters” in conjunction with dependency injection.
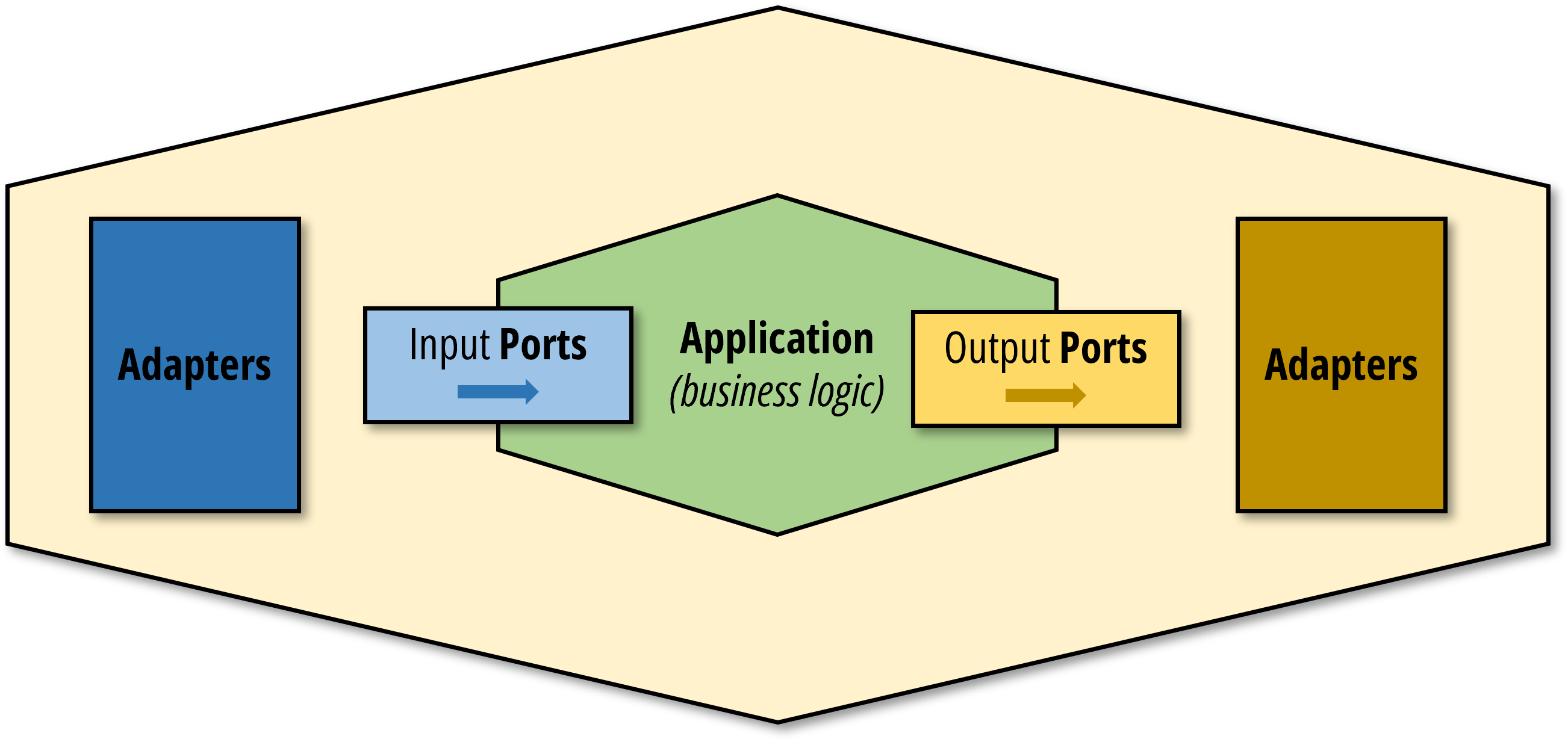
Even though you will not find any class in my codebase named port or adapter, I am always very aware of what my primary and secondary ports are.
In this application, the GitObjectRepository and GitRemoteRepository are examples of output (or secondary) ports. They describe the protocol the application uses to interact with the infrastructure and remote services.
If you browse my source code, you can notice how I created two implementations of the GitObjectRepository: the GitObjectFileRepository which is meant to be used when the application is running; and the GitObjectInMemoryRepository that I used to ease some tests by avoiding the need of writing files to disk and managing their clean up. The ability to have multiple adapters for the same port is a strong advantage of this architectural style.
package infra.persistence;
import core.entities.GitObject;
import core.repository.GitObjectRepository;
import core.utils.HashUtils;
import java.util.HashMap;
/**
* In memory implementation of {@link GitObjectRepository} useful for testing and development.
*/
public class GitObjectInMemoryRepository implements GitObjectRepository {
private final HashMap<String, GitObject> objectsMap = new HashMap<>();
@Override
public GitObject findByHash(String hash) {
return objectsMap.get(hash);
}
@Override
public String save(GitObject gitObject) {
String hash = HashUtils.hashInHexFormat(gitObject.toByteArray());
objectsMap.put(hash, gitObject);
return hash;
}
}
On the input (or primary) side, you will notice I was naughty 😅 and created no interface. Instead, I declared the ports as concrete use cases.
package core.usecases;
import core.entities.GitBlob;
import core.repository.GitObjectRepository;
/**
* Creates a {@link GitBlob} from the provided raw bytes and saves it to the
* {@link GitObjectRepository}.
*/
public class HashObjectUseCase {
private final GitObjectRepository repo;
public HashObjectUseCase(GitObjectRepository repo) {
this.repo = repo;
}
public String hashObject(byte[] blob) {
GitBlob gitBlob = new GitBlob(blob);
return repo.save(gitBlob);
}
}
This is not something I would advise you to do in a professional setup. When working with a team, I prefer to declare interfaces to create better segregation between layers and improve testability. However, in the context of this challenge I didn’t really need them. Take it also as my way to show you that you don’t need to be overly strict with these patterns, as long as you know what you’re doing 😁.
Use Cases
Another interesting decision I made was to prefer "use cases" to "multi-purpose service classes".
Domain entities, value objects or aggregates are not sufficient to implement all the business logic. You typically need a set of services where you place all application specific logic you couldn’t fit elsewhere. Typically, this logic deals with the orchestration of factories, collections of entities and repositories.
It is very common for development teams to define service classes named after the most important entities. If I had a GitObject class, I could go ahead and create a GitObjectServices class where I orchestrate the interaction between the different objects I defined in the model like entities, factories and repositories.
package core.services;
import core.entities.GitBlob;
import core.entities.GitCommit;
import core.entities.GitObject;
import core.entities.GitTree;
import core.enums.GitObjectType;
import core.factories.GitObjectFactory;
import core.repository.GitObjectRepository;
/**
* Sample service class to interact with the {@link core.entities.GitObject} entity.
*/
public class GitObjectServices {
private final GitObjectRepository repo;
public GitObjectServices(GitObjectRepository repo) {
this.repo = repo;
}
public GitObject findByHash(String hash) {
return repo.findByHash(hash);
}
public String createFromBody(GitObjectType type, byte[] body) {
GitObject gitObject = switch (type) {
case BLOB -> new GitBlob(body);
case COMMIT -> new GitCommit(body);
case TREE -> new GitTree(body);
default -> throw new RuntimeException("Invalid type");
};
return repo.save(gitObject);
}
public String createFromRawBytes(byte[] raw) {
GitObject gitObject = GitObjectFactory.createGitObjectFromRawBytes(raw);
return repo.save(gitObject);
}
}That is perfectly fine. However, it might create code that is not very expressive. In my experience, service classes foster code reuse and generalizations over feature specific implementations. Eventually, the more features we support with a single service class, the less clear our code will be increasing the chances of breaking previously implemented features while we introduce new ones.
Use cases are instead focused on delivering a single reusable feature. For this reason, they are way more expressive and tend to be more stable. Once implemented, there are less factors that can force you to modify an already delivered feature.
I felt that in the context of this Git challenge uses cases where a perfect match to deal with each stage in isolation:
InitUseCaseCatFileUseCaseHashObjectUseCaseLsTreeUseCaseWriteTreeUseCaseCommitTreeUseCaseCloneRepositoryUseCase
You will notice that some use cases are extremely lean while others encapsulate more involved algorithms that had no place in the base domain model: e.g. the WriteTreeUseCase
package core.usecases;
import core.entities.GitBlob;
import core.entities.GitTree;
import core.entities.vos.GitTreeEntry;
import core.enums.GitTreeEntryMode;
import core.repository.GitObjectRepository;
import java.io.IOException;
import java.nio.file.DirectoryStream;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class WriteTreeUseCase {
private final GitObjectRepository repo;
public WriteTreeUseCase(GitObjectRepository repo) {
this.repo = repo;
}
public String writeTree(Path workingDir) {
List<GitTreeEntry> entries = new ArrayList<>();
// Scan directory
List<Path> sortedPaths = new ArrayList<>();
try (DirectoryStream<Path> stream = Files.newDirectoryStream(workingDir)) {
for (Path entry : stream) {
sortedPaths.add(entry);
}
Collections.sort(sortedPaths);
for (Path p : sortedPaths) {
if (p.endsWith(".git")) {
continue;
} else if (Files.isDirectory(p)) {
String shaHash = writeTree(p);
entries.add(new GitTreeEntry(GitTreeEntryMode.DIRECTORY, p.getFileName().toString(),
shaHash));
} else {
// Regular file
byte[] content = Files.readAllBytes(p);
GitBlob gitObject = new GitBlob(content);
String shaHash = repo.save(gitObject);
entries.add(new GitTreeEntry(GitTreeEntryMode.fromPath(p), p.getFileName().toString(),
shaHash));
}
}
} catch (IOException e) {
throw new RuntimeException(e);
}
GitTree tree = new GitTree(entries);
return repo.save(tree);
}
}Note that it is also possible to combine use cases and classic services in complex applications. Always use your judgement!
Framework dependencies
The last thing I will mention for what concerns layers and architecture is that if you want to apply clean, onion and hexagonal architectures in a very strict sense, you should keep your application’s core free from dependencies on frameworks.
This is a very tough decision. If you have a project that relies heavily on a framework like Spring or Django, it will be painful to avoid it within the core layer. As usual, use your discretion and figure out what works best for your team.
In this challenge, the only framework I used is picocli and it is relegated to the cli package. This is also the reason why I decoupled commands from use cases. I didn’t want my use cases to depend on this framework or any concern that is specific to the CLI. The use cases are ports that can be invoked by any kind of user interface; not the CLI alone.
package cli;
import core.repository.GitObjectRepository;
import core.usecases.CloneRepositoryUseCase;
import infra.persistence.GitObjectFileRepository;
import infra.remote.HttpGitRemoteRepository;
import java.nio.file.Path;
import picocli.CommandLine;
@CommandLine.Command(name = "clone")
public class CloneCommand implements Runnable {
private final CloneRepositoryUseCase useCase;
@CommandLine.Parameters
private String repoUrl;
@CommandLine.Parameters
private String targetDir;
public CloneCommand() {
this(new GitObjectFileRepository());
}
public CloneCommand(GitObjectRepository repo) {
this.useCase = new CloneRepositoryUseCase(repo, new HttpGitRemoteRepository());
}
@Override
public void run() {
useCase.cloneRepository(repoUrl, Path.of(targetDir));
}
}TDD is not necessary. Testing is.
Something I always believed in is Test-Driven Development (TDD). However, I recently developed an allergy to TDD thanks to all those influencers posting constantly about it on Twitter / X or LinkedIn 😂.
Jokes aside, I know there are big proponents of TDD like Dave Farley for which I have huge respect. However, TDD is not going to guarantee that your code is bug free or higher quality than a codebase written without TDD. Doing TDD properly requires some skill and practice which you cannot build overnight. I’ve seen some development teams trying TDD and eventually giving up because it was too painful for them. Why forcing them?
TDD is also a bad choice if what you are building requires exploration and experimentation which is exactly what I faced in this Git challenge.
That said, don’t overlook testing.
You will notice that my test coverage in this challenge is poor and that I don’t test all layers and features in the same way. However, I know for a fact that I have exactly the right amount of testing that allowed me to refactor the code several times and test several patterns, like decorator and strategy, with confidence.
package core.usecases;
import static org.junit.jupiter.api.Assertions.assertArrayEquals;
import static org.junit.jupiter.api.Assertions.assertEquals;
import static org.junit.jupiter.api.Assertions.assertNotNull;
import core.entities.GitBlob;
import core.utils.ByteArrayUtils;
import core.utils.HashUtils;
import infra.persistence.GitObjectInMemoryRepository;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
class HashObjectUseCaseTest {
private HashObjectUseCase useCase;
private GitObjectInMemoryRepository repo;
@BeforeEach
void setUp() {
repo = new GitObjectInMemoryRepository();
useCase = new HashObjectUseCase(repo);
}
@Test
void hashObject() {
String blob = "Test content";
byte[] expectedByteArray = ByteArrayUtils.concat("blob ".getBytes(),
String.valueOf(blob.getBytes().length).getBytes(), new byte[]{0}, blob.getBytes());
String expectedShaHash = HashUtils.hashInHexFormat(expectedByteArray);
String shaHash = useCase.hashObject(blob.getBytes());
assertEquals(expectedShaHash, shaHash);
GitBlob gitBlob = (GitBlob) repo.findByHash(shaHash);
assertNotNull(gitBlob);
assertArrayEquals(expectedByteArray, gitBlob.toByteArray());
assertEquals(blob, new String(gitBlob.getBody()));
}
}Testing is all about validating what you built and having the confidence to refactor it. Without a proper test suite, you would be very reluctant to change code that is working, because you would have no way to understand if your modifications have altered the application’s behavior in negative.
Conclusion
Summing up, I always build a lightweight domain model of any application I build. With modern diagramming tools like Mermaid, there is no excuse to skip this step. The benefits are multiple but the most important is that it delivers a very quick understanding of what we are building.
The architectural style does not really matter. Do not try to choose between clean, onion or hexagonal architecture with the idea you are going to replicate the layers exactly as described in their diagrams. What matters are the principles behind those diagrams. The most important is keeping your business logic decoupled from concerns like UI and infrastructure.
Finally, don’t underestimate the importance of testing if you want to be able to experiment with different patterns and improve your code as you move along.
Last but not least, share this article with your colleagues if you enjoyed reading it! I would be very grateful if you do so 🙏
Source Code
Source Code is available on GitHub at https://github.com/marcolenzo/codecrafters-git-java
Video
If you want, you can also enjoy this content on YouTube.
How I coded Git