Event Sourcing and CQRS Explained (Are they worth the hassle?)

Event Sourcing and CQRS are possibly the most fascinating architectural patterns in the software world, especially when combined with an event-driven architecture (EDA). In this article, we explain both patterns highlighting advantages and disadvantages of these approaches. In the conclusion, I will give you my personal opinion on whether these patterns are useful or not in our architectures. If you prefer, the same content is available in video form on my YouTube channel.
Event Sourcing Explained
Event Sourcing is an architectural pattern where all state changes are represented as events and recorded in an append-only log. The easiest way to understand this is to compare it to a traditional application.
Imagine we need to develop an API that allows sellers to manage products and their pricing on an e-commerce website. In a typical CRUD application, we would store products as records or documents in a database.

When the seller creates the product a correspondent record is saved on the database. If the seller decides to update the price or any other property of this product, we simply modify the value in the existent record. Our application is persisting only the current state of the product.
This approach is perfectly fine for most scenarios. However, it has one major drawback: data loss. In fact, what would happen if we were requested to provide a history of all changes applied to this product?

In event sourcing, all actions performed by the seller, or any other user, would result in state changes that are recorded as events in an append-only log. When the seller creates a product, a “Product Created” event is generated. Any update to the product is stored as an event as well.
The events are rich in context. They obviously carry the product details, but they can also embed important information like the author, time, and reason for the change.
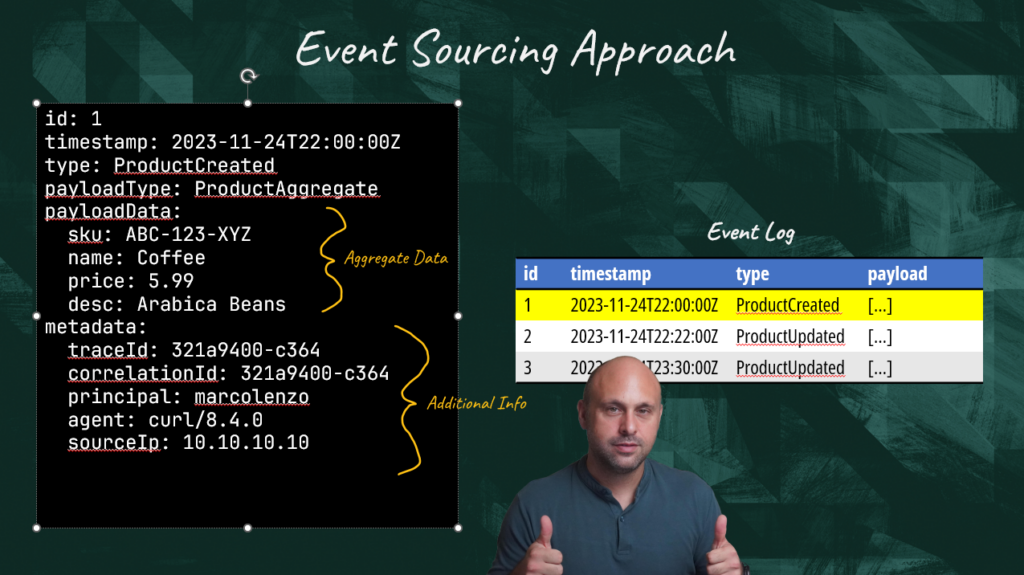
Now we have solved the problem of data loss, but we are not ready yet. In fact, while we can list all the changes that happened in the system, we are now unable to define the current state of the product. This is where the “sourcing” portion of the pattern comes into play.
In order to list products and their details, we still need a view of our domain because it would be difficult and inefficient to figure out the last state of the product by looking at the event log alone. In simpler words, we still need to reconstruct our entity or aggregate. The only difference with the traditional approach is that rather than populating the model by applying changes every time we serve an API request, we source it from the event log.
Now we have both history and current state!
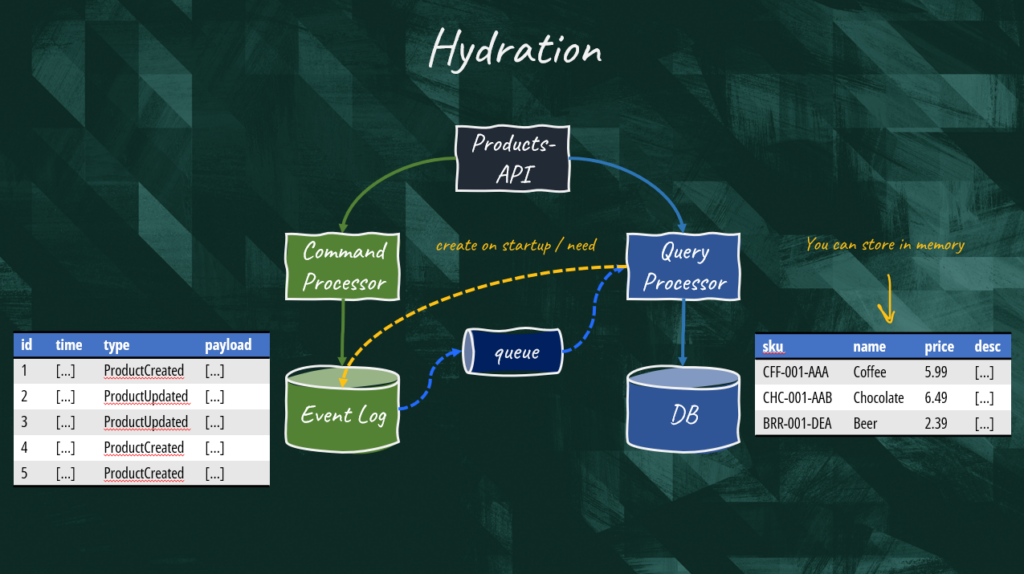
Hydration
The process of reconstructing our domain object is called hydration. In this diagram, we are are showing two approaches. The yellowish line shows the purist event sourcing approach where the the domain object is reconstructed by querying the event log directly and stored in memory. The problem with this methodology is that if we had a large number of products to list, it would be incredibly inefficient. The rest of the diagram shows a more common event-driven architecture (EDA) where events are processed on the fly and the model is continuously persisted in a database so it can be queried more easily. You can consider the database a materialized view of the information stored in the event log.
CQRS Explained
In CQRS, command and query responsibilities are segregated. In simpler words, operations that are meant to change the state of our application are modeled as commands while those that just retrieve the data are modeled as queries. The segregation means that commands and queries must be processed by independent portions of our application or system. In the context of a monolith, CQRS can be achieved defining separate services or modules. In a microservices architecture, we can go a step further and have completely independent microservices.
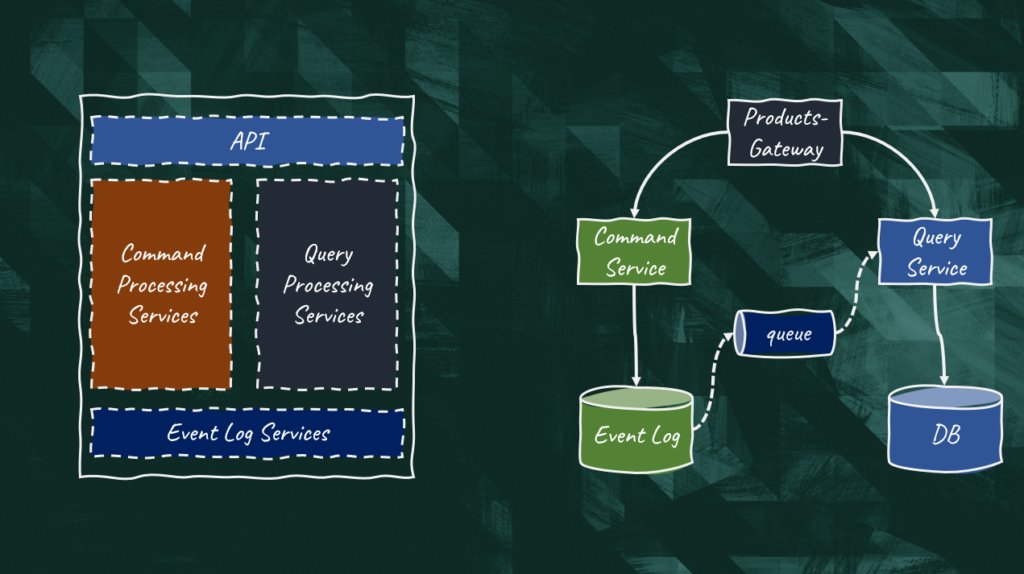
Greg Young introduced this pattern back in 2010 and later described it as a steppingstone towards event sourcing. The reason is obvious.
In event sourcing, the service that populates the event log is dealing with commands, while the service that is materializing the domain model is meant to serve queries. That’s CQRS in action.
Benefits
Now it’s time to answer the question: is event sourcing is as good as it looks?

As usual online you’ll find lists telling you that event sourcing can also solve your back pain. But let’s focus only on the most important ones.
Auditing is number one. It’s undeniable that event sourcing preserves the entire history of our data and protects it from tampering. Events are immutable. We can append events to the log but never modify them. If for any reason we want to revert the change caused by an event, we need to perform a compensating action which would result in an additional event in the log.
Another super cool advantage is the ability to time travel and replay events. Since the domain model is hydrated by processing the events, we can easily go back in time just by pointing to an earlier position in the event log. This can be very useful to debug, perform “what-if” analysis and what I find really awesome is refactoring our domain model. Imagine that for some reason we want to change the structure of our tables or documents in the database or solve some ancient bug. All we need to do is deploy a new version of our application, replay all events, and we’re done! No data migration is necessary! No headaches! The same approach can be used for disaster recovery. As long as we keep our event log well replicated or backed up, we will always be able to reconstruct the current state.
Finally, the last key advantage is that event sourcing fosters low coupling in our system. In fact, event sourcing works really well with an event driven architecture where microservices communicate through messages rather than synchronous API or RPC calls. I’ll link some videos in the that dig deeper into this particular topic.
Drawbacks
And now time for the bad news. Is event sourcing a pattern you should use in your next project? Before I answer, let me show you some drawbacks of this approach.

The list of challenges is very long, and it would require more than one video to cover each point. Let’s make a summary.
We cannot deny that event sourcing increases the complexity of our applications. Nothing comes for free. In a typical application, we just need to populate our database, while in an event sourced system we have the burden of creating and maintaining the event log and hydrating the model from events. That doesn’t come out of thin air. We need to design and code such a solution. We also need to select an event log able to support the load generated by our application. It needs to be able to store a large number of events and potentially serve many requests per second.
There is also the problem that replaying all events to hydrate our model becomes inefficient over time. Queries and application startup can take too long. In that case it might be necessary to persist the model or introduce snapshots events that capture the state of an entity at a certain point in time. It’s a bit like saving the progress on a video game. Rather than starting from scratch, we resume event processing from the last snapshot.
Modifying events is forbidden so changing the format of events is painful. We either lift the restriction, replay all events to create new ones, or use event upcasters that transform the old events format to the new format on the fly.
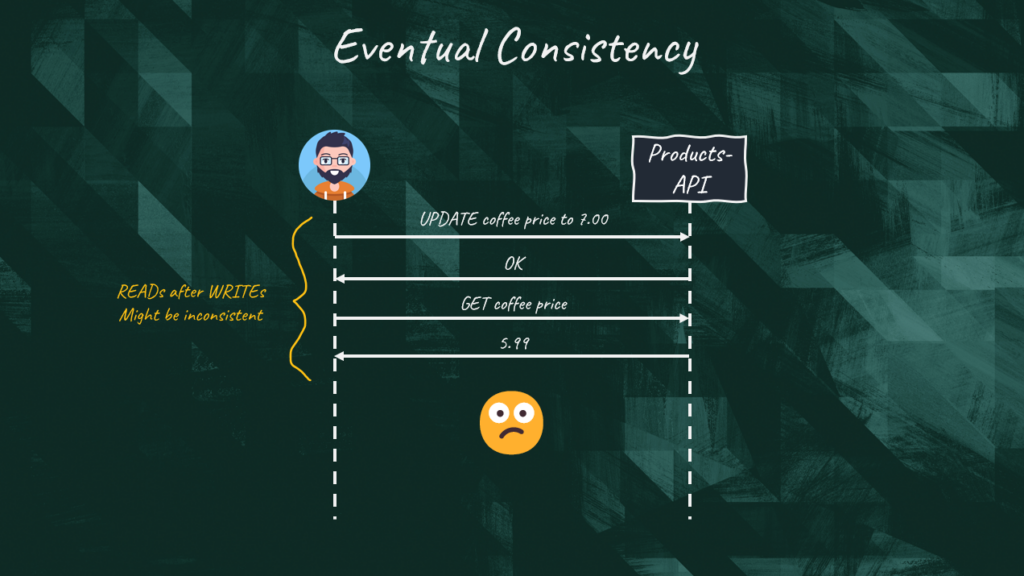
We also need to mention eventual consistency. This can be seen as a benefit and drawback at the same time. It’s a benefit because it helps increase resilience and availability of our system. However, it may complicate life when we attempt a read-after-write. In a typical application, we could perform the update in a single transaction keeping the system always in a consistent state. When implementing event sourcing in conjunction with an event driven architecture, there might be some delay until the action is fully replicated in the system. That means that we can get stale information if we query write after an update.
Sometimes their actions could be conflicting, but the conflict is detected only when the events are processed which is after they are stored in the event log. This is another scenario where we need to solve the conflict with compensating actions.
There’s much more but I want to stop here. If you want to know more, just leave me a comment.
Conclusion
Now time for the conclusion. Should we use event sourcing? My answer is no unless you have a real need for it.
In my opinion, there’s value if you have strict auditing requirements, or if the historical data stored in the event log gives important insights to your business. If that’s not the case, why adding complexity to your architecture? I wouldn’t bother with it unless you want to have fun on a side project just for the sake of learning the pattern.
However, if you really want to try it, I’d suggest having a look at the Axon Framework. It’s incredibly well structured and documented and you can easily get started in a few minutes. Even if you decide to write your own solution, Axon can be a good way to learn how certain challenges of event sourcing can be solved. So make sure to take inspiration from them!
Hope you now have a better idea on what event sourcing and CQRS are. I have many more articles and videos on event driven architecture, domain-driven design and microservices. Make sure to search the blog and visit my YouTube channel!