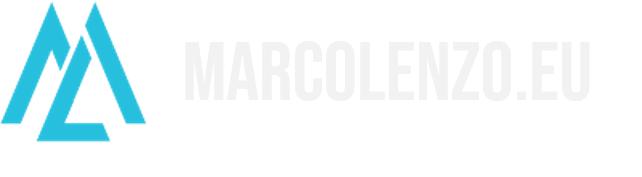
GitOps Explained: Is it worth it?

If you’re thinking of adopting GitOps or want to know more about it, this is the right article for you. I’ll explain it and show its benefits, but most importantly I’ll cover the drawbacks which are not mentioned by other videos or blogs.
I’ll stick to the definition created by the official GitOps Working Group. I’ve seen a lot of popular videos that give their own definition which is not 100% correct. So, let’s fix that and let’s get started.
What’s GitOps?
GitOps is a set of principles for operating and managing software systems. The official definition is that the desired state of a GitOps managed system must be: declarative; versioned and immutable; pulled automatically; continuously reconciled.
These principles are derived from modern software operations (like Infrastructure as Code and DevOps) and are also rooted in pre-existing and widely adopted software development best practices (like version control and continuous integration) that have been in use for at least two decades.
The name derives from the idea that Git acts as the ultimate source of truth and driver of all operations. It was coined back in 2017 by Alexis Richardson, CEO of Weaveworks. At the time, his company had spent over two years provisioning and managing Kubernetes clusters. Let’s see how they came up with the four principles and put them into action with a concrete example.
Declarative
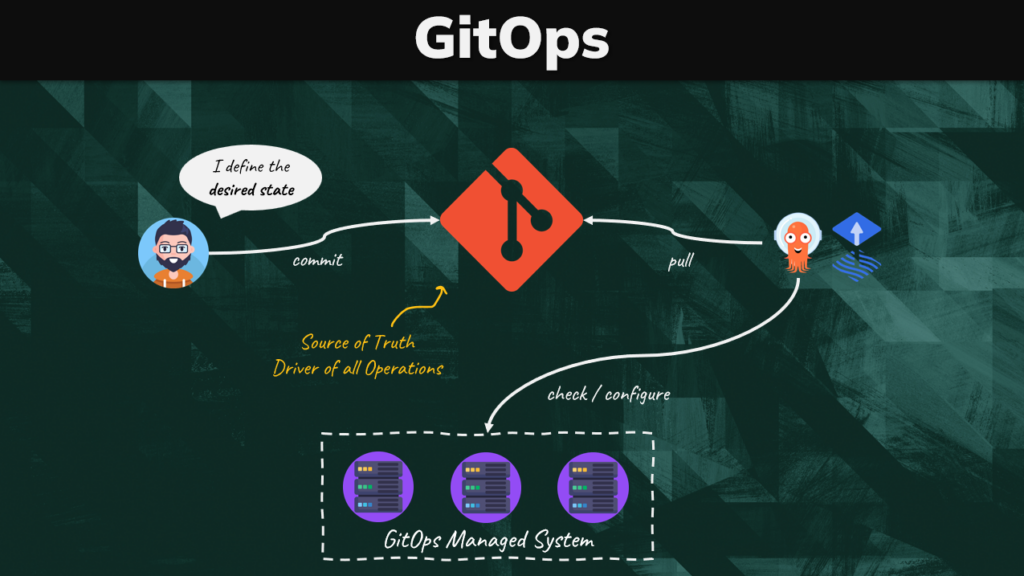
The first principle is that “a system managed by GitOps must have its desired state expressed declaratively”.
Imagine someone wanted to deploy a particular microservice in a target environment. Rather than using a command line tool like kubectl, they thought it was way better to declare their intentions by creating a deployment manifest, which in the scenario of Kubernetes is simply a YAML file.
The main advantage over the imperative approach is that we have a clear separation between the desired state and the implementation necessary to achieve that state. The implementation can be defined separately as commands, scripts, API calls, or even better offloaded to some technology that does the heavy lifting for us, like Puppet, ArgoCD or FluxCD.
Versioned and Immutable
The next principle is that “the desired state is stored in a way that enforces immutability, versioning and retains a complete version history”.
[You don’t say] It’s a no brainer that once we have one or more files describing the desired state of our system, we can commit them to Git or any other version control system with similar characteristics.
A git repository (configured with proper access control) ensures that our changes are immutable, versioned, and auditable. We can easily retrieve the version history to see the contents of a particular commit, together with the author and time the change was committed.
There’s more to it. We can also leverage pull requests to have other engineers review the change and approve it before it’s merged into the target branch.
Pulled Automatically and Continuously Reconciled.
Once a change has been committed and approved, “software agents automatically pull the desired state declarations from the source”.
“Software agents are also responsible for continuously observing the actual system state and attempting to apply the desired state.”
This is possibly the most complex aspect of GitOps so pay attention to this part.
In traditional CI/CD, automation is driven by triggers that act every time a commit is pushed or merged on a particular branch. The issue with this approach is that the system’s actual state can diverge or drift from the desired state and the only chance of correcting it’s by triggering another automation job through a commit. If we have no planned changes, no automation will ever run to correct the divergence.
In GitOps, software agents are responsible not only to pull the desired state from source control but also to continuously verify that the actual system is in the desired state. If they detect a divergence, they are meant to correct it. A divergence could be intentional or unintentional.
It’s intentional when we update the desired state on the state store by committing a new manifest.
It’s unintentional when it’s the state of the actual system that drifts from the desired state. This could happen for many reasons. Maybe there was some manual intervention on the environment, or some component crashed and needs to be recommissioned. The goal is for the desired state and actual state to converge at all times.
So let’s sum it up quickly.
GitOps is all about declaring the desired state of the system and committing it to a versioned repository. Software agents are responsible to continuously monitor the repository and compare the desired state with the actual system state. If they detect a divergence or drift, they correct it to keep desired and actual state always aligned.
Benefits
So, what are the benefits of GitOps? Why should we adopt it?
The GitOps Working Group states that main benefits are:
- Increased Developer and Operational Productivity
- Enhanced Developer Experience
- Improved Stability and Higher Reliability
- Consistency and Standardization
- Stronger Security Guarantees.
It’s evident that GitOps enforces standardization by introducing a well-defined process where engineers and operators are responsible for defining the desired state but not for applying that state. In a system governed by GitOps, operators cannot perform direct updates to the target environment. And this is the biggest win of the GitOps approach.
From a security standpoint, we reduce the number of accounts that need access to our environments. Ideally only software agents have privileges for routine operations and no human intervention should be allowed. This way we also reduce the chance of human error and the possibility that someone performs direct untracked changes on the environments.
It’s obvious that the result is environments that are way more stable and easier to keep consistent. This is a win for both developers and operators.
Drawbacks
And now what about drawbacks?
The biggest challenge with GitOps is that we need to split our CI/CD pipelines across different tools and that makes environment promotions difficult.
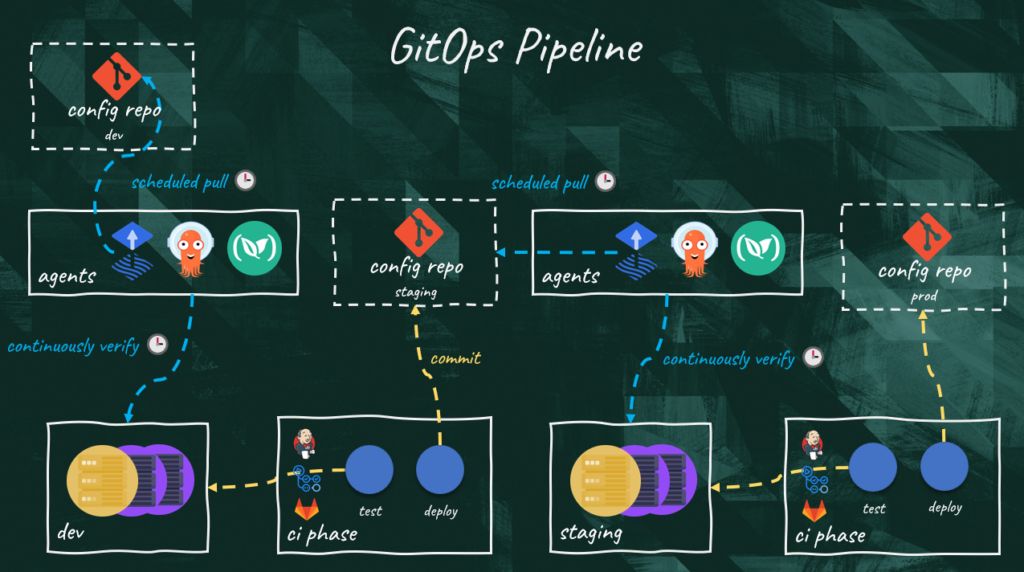
In a typical setup, we can trigger a pipeline by approving a “merge request” on the trunk. The CI/CD tool is in full control and can pull the source code, build it, package it, deploy it to all environments while running different sets of tests.
In a GitOps world such a linear pipeline is not possible because the most popular GitOps tools (like ArgoCD and FluxCD) are incapable of dealing with the continuous integration portion of our pipelines.
That means that we still need the CI solution until the package phase. However, the deployment to an environment must be triggered with a commit on the configuration repository which is monitored by the CD solution.
Now the next problem is deciding when to run the tests since we need a way to know when the application is deployed. Unfortunately, there isn’t a standard approach to do this.
One possible solution is to have the CI and CD tool communicate through notifications. The first notification is sent when we perform the commit on the configuration repository to trigger the reconciliation on the target environment. Once the reconciliation is done, another notification can be used to trigger a new CI pipeline to run the tests, and if successful, to perform another automated commit to promote the change to the next environment.
Conclusion
As you can see GitOps promises higher consistency and security at the cost of fragmented pipelines. My take is that unless we are dealing with few services and environments, this approach can easily become unmanageable. I’m also concerned by auditability because promotion commits are performed by automation, and it might be difficult to correlate the original commit on the application repository with the subsequent ones on the configuration repository.
I admit that I am still trying to learn about this topic. I use GitOps on my personal projects and it works well, but I would like to hear more from your experience on production. Please let me know in the comments!
Don’t forget to like and share the video with your colleagues, so that everyone can learn something new!